Hola de nuevo, en el post anterior construimos un pequeño swarm de 4 nodos y desplegamos un servicio web muy simple. En dicho ejemplo veíamos como el manager creaba copias idénticas de nuestro servicio y las repartía entre los nodos que forman el swarm. Comprobamos que el puerto de nuestro servicio se publicaba en cada uno de los nodos y que, independientemente del nodo al que accediésemos, podíamos conectarnos con nuestro servicio.
En este post vamos a explicar, de manera muy resumida, como funciona la routing mesh en la que participan todos los nodos de un swarm y que nos permite acceder a un servicio independientemente del nodo en el que se encuentre corriendo. Para una explicación mucho mejor os recomiendo, como siempre, consultar la documentación de Docker y en concreto, el siguiente enlace.
Para comenzar vamos a desplegar de nuevo el servicio web simple que usamos especificando que queremos que el número de réplicas sea 1, con lo que el nodo manager desplegará el servicio en uno de los cuatro nodos del swarm:
 |
| Desplegamos el servicio web en el swarm. |
| Comprobamos en que nodo está corriendo el servicio. |
Como vemos el contenedor está corriendo en el nodo 3 del swarm y si comprobamos los puertos en los que están escuchando los 4 nodos veremos que, en todos ellos, el puerto 443 está disponible en la red de servicio. Por tanto, si nos conectamos a cualquier nodo del swarm salvo el 3, comprobamos que efectivamente, nuestro servicio web está disponible:
 |
| Acceso al servicio web desde un nodo sin réplica. |
En definitiva la pregunta que nos hacemos es, ¿como puedo acceder al servicio desde cualquier nodo del swarm si este solo está corriendo en uno de los nodos? La respuesta a esta pregunta es el sistema de enrutamiento del swarm.
Cuando creamos un swarm, todos los nodos del mismo participan en lo que Docker denomina una malla de enrutamieno de entrada (ingress routing mesh) mediante la cual, todos los miembros del swarm son capaces de enrutar las peticiones de conexión entrantes a los nodos donde realmente se encuentran los contenedores.
Esto quiere decir que, cuando desplegamos un servicio y publicamos un puerto, este puerto pasa a estar enlazado en los interfaces que hayamos definido como interfaces de datos en todos los hosts del swarm. El motor de Docker crea la malla de enrutamiento, que escucha en los puertos publicados en todos los hosts, y enruta cualquier petición entrante al swarm a dicho puerto hacia un contenedor activo, aunque este se encuentre en un host diferente.
De forma muy simplificada, podemos verlo del siguiente modo:
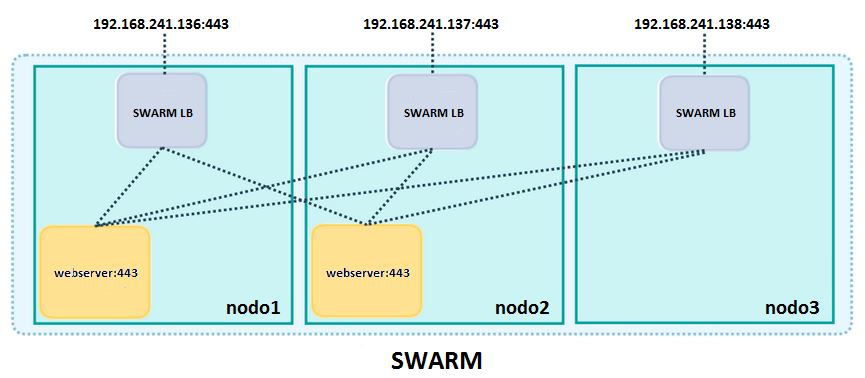 |
| Malla de enrutamiento de entrada en un Docker swarm. |
Por tanto, cada vez que llegue una petición a un host de nuestro swarm en un puerto publicado para un servicio, el nodo que reciba dicha petición lo enrutará a un contenedor activo aunque este se encuentre en otro host.
Como es lógico, necesitaremos balanceadores de carga para tener un único punto de acceso a nuestro swarm, lo cual veremos más adelante.