En la anterior entrada de esta serie, repasamos como funciona la red entre contenedores que están encapsulados en el mismo POD o que están en PODs diferentes, pero todos se encuentran en el mismo nodo del cluster.
Como también vimos, en un sistema real tendremos un cluster de Kubernetes formado por diferentes nodos y por tanto, es importante que comprendamos perfectamente como se comunican los PODs entre si cuando estos se encuentran en hosts diferentes. Teniendo esto en cuenta, de forma muy simple, un cluster de Kubernetes de N nodos será algo como lo siguiente:
 |
| Comunicaciones entre nodos de un clsuter. |
Con este diagrama de red podemos decir que, como es lógico, cada host o nodo miembro del cluster puede comunicarse con el resto usando el interfaz eth0 ya que todos se encuentran en la misma red. Pero, si recordamos lo que vimos en el post anterior de esta serie, lo que realmente tenemos es algo como lo siguiente:
 |
| Comunicaciones entre todos los elementos de un cluster. |
Esta imagen nos permite darnos cuenta de la complejidad que tienen las comunicaciones entre todos los miembros de un cluster de Kubernetes ya que, por defecto, puede suceder que las direcciones IP internas de todos los componentes, como el bridge virtual cni0 o las direcciones IP asignadas a los interfaces veth, coincidan en dos o más de los nodos que forman parte del cluster. Aunque es el peor caso que se puede dar, incluso aunque todas las direcciones IP fuesen diferentes, un nodo que forma parte del cluster no tendría forma de saber, a priori, que direcciones IP tienen el resto de bridges o interfaces veth del resto de nodos del cluster.
Esto podemos comprobarlo con un cluster muy simple, formado por un nodo master y dos nodos worker. Partiendo de este cluster, en el cual empleamos cri-o como motor de contenedores, podemos ver lo siguiente si lanzamos un deployment simple para crear una réplica de un contenedor en cada uno de los nodos worker:
 |
| Deployment en un cluster de kubernetes recién creado. |
Como se puede comprobar en la imagen anterior, ambos contenedores tienen la misma dirección IP, la cual se corresponde al rango de direcciones IP proporcionadas por el motor de contenedores que está instalado en cada nodo del cluster, en este caso cri-o.
Además, como es lógico, las direcciones IP de los interfaces de red bridge a los que se conectan los contenedores es la misma en todos los nodos:
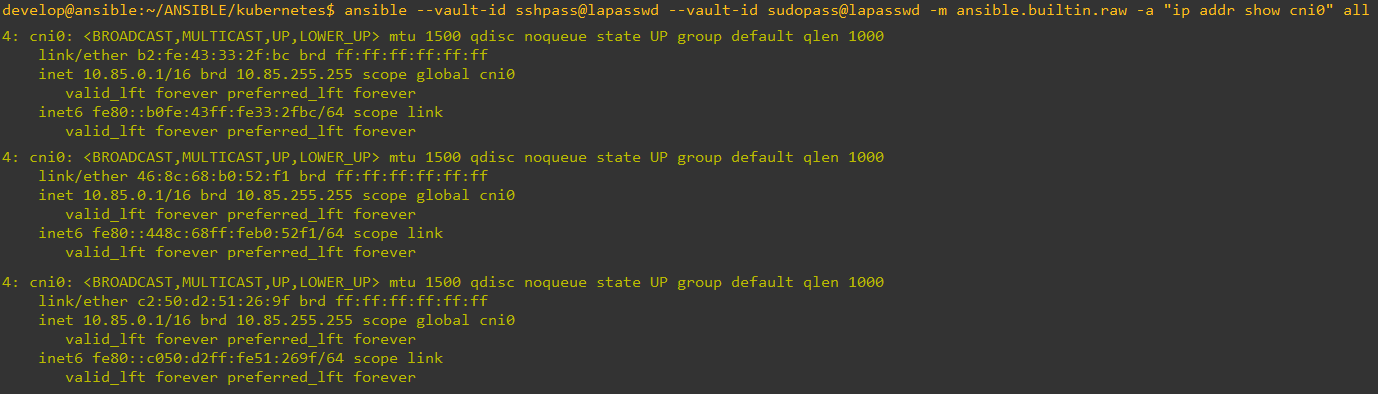 |
| Direccionamiento IP de interfaz bridge cni0 en los nodos del cluster. |
Es importante que recordemos que, en todos los nodos, tenemos instalado el mismo motor de contenedores. Este motor se encarga de asignar direcciones IP a los PODs, en función de la configuración por defecto del mismo y Kubernetes es la capa de orquestación que controla el motor, pero no controla la asignación de direcciones IP. En resumen, este comportamiento es el esperado en un cluster de Kubernetes recien instalado.
Evidentemente, las comunicaciones entres los PODs que se encuentran en diferentes nodos, es totalmente imposible ya que las direcciones IP son iguales y no hay manera de enrutar los paquetes correctamente entre ellos.
Para poder solventar este problema y asegurar la correcta comunicación entre todos los PODs del cluster, es necesario que instalemos un plugin de red CNI. Este plugin de red, basándose en la configuración que apliquemos, hará dos cosas, primero asignará un rango de direcciones IP global a los bridges en cada nodo y dentro de ese rango de direcciones, asignará una dirección IP al interfaz bridge en función del nodo donde se construya dicho interfaz. Adicionalmente añadirá reglas de enrutamiento en el nodo, indicando que interfaz físico es el primer salto o gateway para alcanzar las direcciones de red de cada uno de los bridges correspondientes al resto de nodos. De esta manera, aseguramos la correcta comunicación entre todos los PODs que puedan ejecutarse en el cluster.
Por tanto el plugin o add-on de red, el cual es totalmente necesario para permitir las correctas comunicaciones entre todos los elementos del cluster, nos permite establecer la comunicación entre todos los PODs del cluster.
Podemos simular esto si modificamos la configuración del rango de red proporcionado por el motor de contenedores y añadimos rutas de red en los nodos worker. Por ejemplo, podemos hacer lo siguiente en los nodos worker:
 |
| PODs arrancados con direcciones IP de subredes diferentes. |
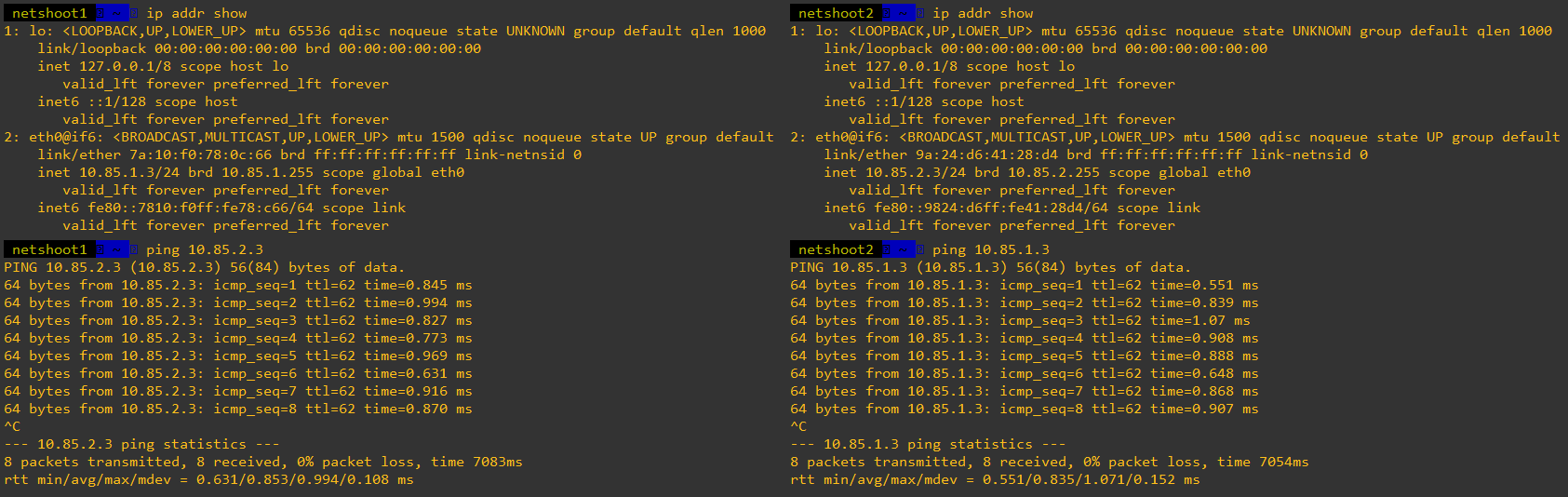 |
| Comunicación entre PODs. |
Esto que hemos realizado a mano, es lo que básicamente implementa el plugin de red CNI que tenemos que instalar en nuestros clusters de Kubernetes para permitir las comunicaciones entre los PODs que se encuentren en diferentes nodos. En general, un plugin de red, se encargará de la asignación de direcciones IP a los interfaces bridge de los nodos, asignación de direcciones IP a los diferentes PODs que corren en cada uno de ellos y creación de todas las rutas necesarias para permitir estas comunicaciones. Adicionalmente, algunos plugins ofrecen además características como el control de red mediante políticas, permitiendo controlar las comunicaciones entre los diferentes PODs, así como entre estos y el exterior del cluster.
En resumen, para permitir las comunicaciones entre todos los PODs de un cluster de Kubernetes, es necesario que instalemos un plugin de red CNI, el cual controlará todos los aspectos de red necesarios para implementar el modelo de red de Kubernetes, así como funcionalidades adicionales dependiendo del plugin que utilicemos.


























































