Hoy continuamos explorando Docker swarm pero, para variar un poco, vamos a instalar Rancher para crear y administrar un swarm de dockerhosts así como para explorar las funcionalidades que puede aportar a nuestros despliegues de Docker swarm.
¿Que es Rancher? es una plataforma de gestión de contenedores que nos permite su despliegue y control en cualquier entorno, desde nuestros propios servidores, ya sean físicos o virtuales o en entornos cloud. Además proporciona una gran cantidad de funcionalidades adicionales que pueden ser desplegadas desde diferentes catálogos, lo que permite añadir nuevas herramientas a nuestros despliegues de forma rápida y sencilla.
De forma muy resumida, la unidad de trabajo básica de Rancher es el entorno, cada uno de los cuales puede utilizar un tipo de orquestación y que contendrá los hosts asociados a dicho entorno. Como siempre, para una información más detallada y mucho mejor que esta, os recomiendo visitar la página oficial de Rancher.
¿Que es Rancher? es una plataforma de gestión de contenedores que nos permite su despliegue y control en cualquier entorno, desde nuestros propios servidores, ya sean físicos o virtuales o en entornos cloud. Además proporciona una gran cantidad de funcionalidades adicionales que pueden ser desplegadas desde diferentes catálogos, lo que permite añadir nuevas herramientas a nuestros despliegues de forma rápida y sencilla.
De forma muy resumida, la unidad de trabajo básica de Rancher es el entorno, cada uno de los cuales puede utilizar un tipo de orquestación y que contendrá los hosts asociados a dicho entorno. Como siempre, para una información más detallada y mucho mejor que esta, os recomiendo visitar la página oficial de Rancher.
Después de un poco de rollo teórico vamos a instalar Rancher, para lo cual he seguido las instrucciones de instalación dadas en esta página para un entorno multinodo, en el cual he desplegado cuatro máquinas virtuales, siendo una de ellas el servidor de base de datos y las otras tres los nodos donde he instalado Docker.
Para comenzar la instalación, solo necesitamos lanzar el siguiente comando en al menos uno de los hosts:
Como es lógico este comando descargará la imagen de correspondiente de Docker Hub y creará un contenedor para nuestro servidor Rancher, el cual conectará con el servidor de base de datos indicado en los parámetros del comando docker run. Tras ejecutar el comando anterior podemos comprobar que hay un contenedor en nuestro host que se corresponde con el servidor Rancher:
En la pantalla para añadir un nuevo host a la infraestructura, es recomendable incluir la dirección IP del host para asegurar que no haya problemas de comunicación, sobre todo al registrar el dockerhost que contiene el propio servidor de Rancher.
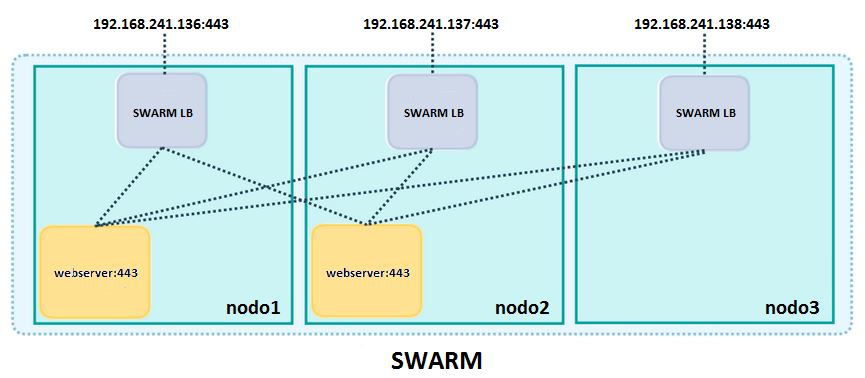
Es muy importante recordar que estamos creando un swarm con varios dockerhosts, con lo que es necesario que creemos las reglas necesarias en los firewalls de cada nodo para asegurar el correcto funcionamiento del swarm. Relacionado con esta correcta configuración del cortafuegos de los dockerhosts, un punto importante a tener en cuenta para registrar correctamente el dockerhost donde se está ejecutando el contenedor con el servidor Rancher, es que debemos añadir el interfaz docker0 a la zona trusted del firewall o bien definir las reglas correspondientes para permitir las conexiones a la dirección IP física del host teniendo en cuenta el interfaz docker0 y las conexiones salientes desde el contenedor agente.
Una vez que hayamos realizado los pasos anteriores para todos nuestros nodos virtuales, incluyendo el dockerhost en el que se encuentra el propio servidor de Rancher, la infraestructura de nuestro entorno será similar a la siguiente:
Para comenzar la instalación, solo necesitamos lanzar el siguiente comando en al menos uno de los hosts:
| Instalación del nodo servidor de Rancher. |
 | |||||||
| Host con el contenedor del servidor Rancher. |
A continuación ya podremos acceder a la consola de administración de Rancher, con lo que solo necesitamos lanzar un navegador y acceder al puerto 8080 del host donde hemos lanzado el contenedor del servidor Rancher. Al acceder por primera vez a la consola nos encontraremos con una imagen como la siguiente:
 |
| Conosla de administración de Rancher. |
En este punto, lo primero es configurar el control de acceso a la consola y configurar el método de autenticación que vayamos a utilizar. En nuestro ejemplo, usaremos autenticación local por sencillez. Para configurar el control de acceso solo tenemos que acceder a la sección Access Control dentro del menú ADMIN y crear la cuenta de usuario con derechos de administración que vayamos a utilizar:
 |
| Configuración del control de acceso a la consola de Rancher. |
A continuación debemos crear un nuevo entorno usando la plantilla disponible para Docker swarm. Para crearlo solo es necesario pinchar sobre el botón Add Environment desde la sección Manage Environments del menú Default, que nos indica cual es el entorno que estamos gestionando:
Tras crearlo, ahora veremos nuestros dos entornos disponibles en la ventana de gestión de entornos y que el entorno por defecto es el entorno llamado Default:
Ambos entornos se encuentran en estado Unhealthy ya que no hemos añadido hosts a ninguno de ellos. Por tanto, el siguiente paso consiste en añadir hosts a la infraestructura de nuestro nuevo entorno, para ello solo tenemos que cambiar al entorno Swarm test lab y acceder a la sección Hosts del menú INFRASTRUCTURE para añadir nuestros dockerhosts. El proceso, muy resumido, podemos verlo en las siguientes imágenes:
 |
| Ventana para la gestión de entornos en Rancher. |
 |
| Creación de un entorno Docker Swarm |
 |
| Entornos disponibles tras la creación del entorno para Swarm. |
 |
| Definición de la infraestructura para establecer nuestro Swarm. Rancher indica que debemos añadir hosts. |
 |
| Añadimos un dockerhost a la infraestructura de nuestro entorno Docker Swarm. |
Es muy importante recordar que estamos creando un swarm con varios dockerhosts, con lo que es necesario que creemos las reglas necesarias en los firewalls de cada nodo para asegurar el correcto funcionamiento del swarm. Relacionado con esta correcta configuración del cortafuegos de los dockerhosts, un punto importante a tener en cuenta para registrar correctamente el dockerhost donde se está ejecutando el contenedor con el servidor Rancher, es que debemos añadir el interfaz docker0 a la zona trusted del firewall o bien definir las reglas correspondientes para permitir las conexiones a la dirección IP física del host teniendo en cuenta el interfaz docker0 y las conexiones salientes desde el contenedor agente.
Una vez que hayamos realizado los pasos anteriores para todos nuestros nodos virtuales, incluyendo el dockerhost en el que se encuentra el propio servidor de Rancher, la infraestructura de nuestro entorno será similar a la siguiente:
 |
| Infraestructura de nuestro entorno Docker swarm con tres dockerhosts. |
Revisando la imagen anterior, ¿que es lo que ha hecho Rancher? Pues como vemos ha creado un swarm en el que todos los hosts tiene el rol de manager y ha desplegado en ellos una serie de contenedores que implementan los servicios de infraestructura necesarios. Desde el menú SWARM podremos comprobar que el estado de toda la infraestructura del entorno es correcta:
 |
| Infraestructura del entorno swarm. |
 |
| Servicios de infraestructura desplegado por Rancher en el swarm. |
Como veremos en entradas futuras sobre Rancher, cada uno de estos servicios de infraestructura desempeñan una función determinada para el correcto funcionamiento de nuestro entorno y Rancher los implementa mediante un contenedor dedicado en cada dockehost.
En este punto tenemos un swarm el cual está controlado por Rancher, con lo que el siguiente paso es desplegar un servicio simple. Para esto, basta con acceder a la sección Containers del menú INFRASTRUCTURE y pinchar sobre Add Container:
Como vemos, en las diferentes pestañas tenemos las opciones de configuración disponibles para nuestro contenedor. Estableciendo una configuración básica para nuestro ejemplo y pinchando sobre el botón Create se seguirá el proceso de descargar la imagen de Docker Hub y crear el contenedor con la configuración que hemos especificado. Una vez creado Rancher nos mostrará las estadísticas de rendimiento del contenedor así como sus parámetros de configuración:
Portainer es un interfaz gráfico que nos permite administrar entornos Docker y está incluido como uno de los servicios de infraestructura desplegados por Rancher. Una vez que accedemos al interfaz de portainer, la consola de administración es como podemos ver en la siguiente imagen:
En este punto tenemos un swarm el cual está controlado por Rancher, con lo que el siguiente paso es desplegar un servicio simple. Para esto, basta con acceder a la sección Containers del menú INFRASTRUCTURE y pinchar sobre Add Container:
 |
| Apartado contenedores del entorno docker swarm. |
Al crear un contenedor a partir de una imagen, nos encontramos con todas las opciones disponibles en línea de comandos cuando estamos administrando Docker. Así, para nuestro ejemplo tenemos lo siguiente:
 |
| Definición de parámetros de configuración de un contenedor. |
 |
| Estadísticas de uso de nuestro contenedor. |
Este contenedor no lo hemos definido como un servicio y por tanto, solo será accesible desde el nodo en el cual se esté ejecutando. Para crear un servicio debemos crear un stack, para lo cual debemos definir un archivo docker-compose.yaml que contenga la descripción de nuestro servicio o bien, usar uno de los servicios de infraestructura que Rancher ha desplegado al crear nuestro swarm. Este servicio de infraestructura se llama Portainer y se encuentra disponible en el menú SWARM:
 |
| Acceso a Portainer desde el menú SWARM. |
 |
| Pantalla de acceso al interfaz de administración Portainer. |
 |
| Interfaz de administración de Portainer. |
Usando Portainer, podemos desplegar un servicio de forma muy sencilla desde el apartado Services con solo especificar los parámetros de configuración necesarios para nuestro servicio:
 |
| Creación de un servicio desde Portainer. |
 |
| Panel de control de los servicios desplegados. |
Ahora desde el interfaz de Rancher, en la sección Containers de nuestra infraestructura vemos los contenedores que están ejecutándose:
 |
| Los contenedores de nuestro servicio vistos desde Rancher. |
Por tanto, y en resumen, podemos crear y gestionar nuestros entornos Docker Swarm desde Rancher y lo más importante es que añade nuevas funcionalidades gracias a los servicios de infraestructura que despliega.
Adicionalment nos permite tener un análisis de uso de los contenedores de nuestros servicios y controlarlos directamente, aunque desde mi punto de vista lo recomendable es que usemos Portainer directamente ya que nos da acceso a las acciones de servicio.
En las próximas entradas sobre Docker Swarm y Rancher desplegaremos servicios, describiéndolos con los ficheros compose correspondientes e investigaremos los servicios de infraestructura disponibles y como podemos utilizarlos.
NOTA IMPORTANTE: Es necesario establecer el parámetro de configuración max_allowed_packet de nuestra base de datos, si usamos MySQL o MariaDB, en al menos 32M para que Rancher pueda refrescar correctamente el catálogo de plugins y plantillas de los repositorios de Rancher.