Hoy vamos a estudiar cómo podemos extender las funcionalidades de Docker mediante el uso de plugins.
Docker y por tanto Docker Swarm, al igual que orquestadores como Kubernetes o Rancher, permite el uso de plugins o módulos adicionales que nos permitirán la integración de nuestra infraestructura de contenedores con otros servicios o añadirán funcionalidades adicionales. Estos plugins, disponibles en Docker Hub, nos permiten integrar nuestros dockerhosts con sistemas de almacenamiento, añadir funcionalidades de logging o extender las capacidades de red.
Para estudiar el funcionamiento del sistema de plugins de Docker, voy a centrarme en el plugin Trident desarrollado por NetApp, que nos permite administrar y montar volúenes alojados y servidos por sistemas NetApp en nuestros dockerhosts.
 |
| Plugin Trident de NetApp disponible en Docker Hub. |
En la página del plugin en Docker Hub tenemos disponible la descripción del plugin así como las instrucciones de instalación del mismo, pero es recomendable seguir las instrucciones de configuración oficiales dadas en el siguiente
enlace.
En resumen, para usar este plugin debemos realizar los siguientes pasos:
- Debemos crear el fichero de configuración en todos los dockerhosts que vayamos a integrar con nuestros sistemas NetApp.
- Crearemos una o más SVMs que proporcionarán los servicios de bloque o fichero necesarios. Es muy importante que dichas SVMs tengan asignado uno o más agregados para la creación de volúmenes.
- Creamos un rol y un usuario específico para el uso del plugin en cada una de las SVMs que vayan a proporcionar servicio a nuestros dockerhosts.
- Por último instalamos el plugin en todos nuestros dockerhosts.
Empecemos por el fichero de configuración, como indica la documentación este fichero debe estar en la ruta /etc/netappdvp y es un fichero JSON cuyo nombre por defecto será config.json. Una configuración simple del fichero, para un entorno NAS, podría ser:
 |
| Fichero de configuración de Trident. |
En esta configuración estoy especificando:
- Los parámetros managementLIF y dataLIF contienen el nombre DNS o dirección IP de las LIF de gestión y datos de la SVM para esta instanacia de configuración.
- El parámetro svm indica el nombre de la SVM que estamos usando, siendo username y password las credenciales del usuario que usaremos para interactuar con dicha SVM.
- La sección default establece una serie de valores por defecto para la creación de nuestros volúmenes desde los dockerhosts. En este ejemplo establecemos la política de snapshots así como la política de exportación de volúmenes, el tamaño de los volúmenes creados, el tipo de seguridad y la reserva de espacio para snapshots.
En caso de cambiar la configuración de Trident, será necesario reiniciar el plugin con los comandos docker plugin disable y docker plugin enable.
Creamos una SVM con el mismo nombre que el que indicamos en el fichero de configuración, así como el rol con los permisos adecuados que luego asignaremos al usuario que tabién vamos a crear. Los permisos necesarios para el rol son los siguientes:
 |
| Creación del rol necesario para el plugin. |
Creamos el usuario y le asignamos el rol que acabamos de crear, es importante que establezcamos como tipo de aplicación a usar por el usuario ontapi:
 |
| Creación del usuario y asignación del rol. |
Ahora ya podemos instalar el plugin en todos nuestros dockerhosts, siendo la salida de la instalación como la siguiente:
 |
| Instalación del plugin Trident en los dockerhosts. |
 |
| El plugin ya instalado y disponible. |
Una vez instalado el plugin, al estar habilitado, el demonio docker se encargará de arrancarlo cada vez que iniciemos el sistema. Podemos comprobarlo viendo los procesos de cada uno de nuestros dockerhosts:
 |
| Procesos del plugin Trident. |
En caso de ser necesario, podemos parar el plugin usando el comando docker plugin del siguiente modo:
 |
| Parando el plugin Trident en un dockerhost. |
Como ya he comentado la SVM debe tener agregados asignados a ella para permitir la creación de volúmenes desde el plugin. En caso de no ser así recibiríamos un error como el siguiente:
 |
| Error cuando la SVM no tiene agregados asignados. |
Desde OnCommand System Manager podemos asignar de forma muy rápida y simple los agregados a la SVM con solo editarla desde el apartado SVMs:
 |
| Asignamos un agregado a nuestra SVM para el usuao de Trident. |
Lo primero que podemos hacer es crear los volúmenes que vayamos a necesitar usando el comando docker volume. Como es lógico esto solo lo haremos desde uno de nuestros dockerhosts, así que como ejemplo creamos varios volúmenes desde diferentes dockerhosts:
 |
| Creamos varios volúmenes usando el plugin Trident. |
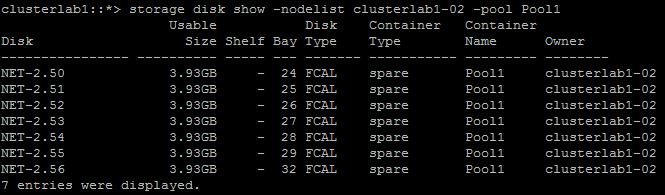
 |
| Comprobamos que los nuevos volúmenes existen en el agregado. |
Es muy importante que nos demos cuenta que al delegar un agregado a la SVM como hemos hecho, el usuario que utilicemos tiene control total sobre los volúmenes que existan en dicho agregado. Por tanto, si el agregado está compartido con más clientes, es posible borrar el resto de volúmenes con los comandos de gestión de volúmenes de Docker a través de Trident, siempre y cuando todos los volúmenes de dicho agregado contengan el mismo prefijo que hemos establecido en la configuación del plugin. Por ejemplo, si listamos los volúmenes disponibles vemos que aparece uno que no hemos creado con Trident:
 |
| Listado de volúmenes disponibles. |
Para evitar problemas, si es necesario que diferentes cliente compartan el mismo agregado, lo mejor es que los volúmenes controlados por Trident utilicen un prefijo distinto al del resto de volúmenes del agregado.
Una vez creados los volúmenes, podemos pasar a usarlos montándolos cuando despleguemos un contenedor o un servicio en nuestro swarm:
 |
| Creación de un servicio replicado con un volumen. |
El comando anterior utiliza la sintaxis mount para el montaje de volúmenes, esta sintaxis está disponible desde la versión 17.06 de Docker para contenedores standalone y no solo para swarm. En próximas entradas explicaré más detalladamente como utilizarla y sus diversas opciones, por ahora quedémonos en que vamos a montar un volumen controlado por el plugin Trident.
Al ejecutar el comando anterior, swarm orquesta el montaje del volúmen especificado en los hosts en los que se despliegue un contenedor que lo necesite, con lo que, de forma automática montará por NFS el volumen swarm_HTML que hemos creado anteriormente y que está sirviendo nuestra SVM. Esto lo podemos comprobar del siguiente modo:
 |
| Escalamos el servicio a 3 réplicas. |
Ahora el contenedor solo está corriendo en tres de los dockerhosts que forman el swarm, con lo que el volumen necesario solo está montado en dichos hosts como podemos ver:
 |
| Docker Swarm ha montado el volumen en los hoosts necesarios. |
Si ahora escalamos de nuevo el servicio, comprobaremos que se montará el volumen en el nodo swarm-nodo2 para poder levantar correctamente el contenedor con el volumen requerido:
 |
| Docker Swarm monta el volumen en el nodo restante. |
Como es lógico, al borrar el servicio, el volumen se desmontará de todos los nodos si ningún otro servicio lo está utilizando.
Por tanto, y en resumen, hemos visto como Docker Swarm es capaz de orquestar perfectamente el montaje de volúmenes externos, en este caso controlados por el plugin Trident de NetApp y como este plugin nos permite integrar nuestra infraestructura de contenedores basada en Docker con los sistemas de almacenamiento NetApp. Además hemos podido comprobar como expandir las funcionalidades de Docker mediante el uso de plugins.
Como es lógico este plugin también está disponible para Kubernetes, el cual espero poder estudiar dentro de un tiempo y repasar su funcionamiento.
En próximas entradas, repasaré las opciones disponibles para la gestión y uso de volúmenes en servicios implementados en Docker Swarm con la opción mount.