Aprovechando un rato libre, es momento de continuar con la implementación de un servidor de nombres y autenticación basado en OpenLDAP y Kerberos.
En las entradas anteriores de esta serie, fuimos añadiendo servicios sobre la base de un servidor OpenLDAP y llegamos a un punto donde teníamos un servidor de nombres implementado mediante un servidor OpenLDAP, un servidor de autenticación implementado mediante Kerberos y un servidor DNS, usando PDNS. Configuramos Kerberos y el servidor DNS para que usaran OpenLDAP como backend, para lo cual creamos DNs específicos dedicados a cada servicio. Estos DNs permiten a cada servicio realizar consultas o modificaciones, en caso de ser necesario, de la información contenida en el servidor OpenLDAP.
Hoy veremos como integrar un servicio, en este caso PDNS, para que utilice tickets de Kerberos para poder realizar consultas al servidor OpenLDAP en vez de emplear un par DN/contraseña. El objetivo de esta integración consiste en aumentar la seguridad de la infraestructura, además de asegurar que no hay contraseñas de servicio, aunque sean encriptadas, en los ficheros de configuración de los servicios.
Para realizar esta integración es importante recordar, de forma resumida, el flujo de autenticación de Kerberos, teniendo en cuenta que las dos entidades implicadas en este caso son dos servicios que se ejecutarán en el mismo host o en dos hosts separados y por tanto, uno de los servicios actuará como cliente:
- El servicio cliente, en este caso PDNS, ha sido configurado para autenticarse mediante el uso de GSSAPI, con lo que envía la clave almacenada en su keytab al KDC (Key Distribution Center) solicitando un TGT (Ticket Granting Ticket).
- El KDC valida la clave enviada por el servicio remoto y genera el TGT correspondiente.
- El servicio PDNS recibe el TGT, lo que le permitirá solicitar tickets para acceder a otros servicios.
- Empleando el TGT, el cliente solicita al KDC un ticket de servicio para poder consultar el servidor OpenLDAP.
- El KDC recibe la solicitud y tras validarla, devuelve el ticket de servicio correspondiente al cliente.
- El servicio cliente consulta al servicio remoto empleando el ticket de servicio proporcionado por el KDC.
Este flujo de validación que acabamos de ver implica los siguientes puntos:
- En el dominio o reino Kerberos existente debemos crear los principales
necesarios para ambos servicios, tanto el del cliente como el del servidor.
- El servicio cliente debe disponer de la clave necesaria en un keytab accesible por el mismo.
- El servicio cliente debe configurarse para emplear GSSAPI.
- El servicio servidor debe estar configurado para permitir el acceso mediante Kerberos y disponer de un keytab.
- El servicio servidor debe configurarse para acepta GSSAPI como mecanismo de autenticación.
Para implementar todo esto, vayamos punto por punto y empecemos por saber que es un keytab. De forma simple, un keytab es un fichero que almacena claves de kerberos para uno o más principales. En concreto un fichero keytab almacenará la fecha de escritura de la entrada en el fichero, el nombre del principal, un número de versión de la clave que representa la entrada, un tipo de encriptación y la propia clave.
Conviene recordar que un principal o Service Principal Name (SPN) es una entrada en un reino Kerberos, tanto de usuarios como de servicios, con un formato como el siguiente:
Servicio/Nombre de Host@REINO Kerberos
Servicio/Nombre de Host.Dominio@REINO Kerberos
Nombre de Usuario@Reino Kerberos
Los dos primeros tipos suelen emplearse para representar servicios, mientras que el último se utiliza para representar usuarios. Por tanto, en nuestro caso, es necesario que creemos cuatro SPNs nuevos, dos para el servicio LDAP y otros dos para el servicio PDNS, a partir de los cuales podremos crear los keytabs correspondientes.
Teniendo en cuenta lo expuesto hasta aquí, creamos el
principal correspondiente para cada servidor LDAP de nuestra infraestructura y los exportamos a un
keytab:
 |
Creación principal - Servidor ldap1
|
 |
Creación principal - Servidor ldap2
|
 |
Exportación keytab servidor ldap1.
|
 |
| Exportación keytab servidor ldap2. |
Ahora realizamos el mismo proceso de creación de SPNs y exportación de los keytab correspondientes para el servicio PDNS, que actuará como cliente del servicio OpenLDAP. ¿Como hacemos esto? Pues como se ve a
continuación:
 |
Creación principal - Servidor PDNS1.
|
 |
| Creación principal - Servidor PDNS2. |
Ahora, al igual que en el caso de los principales de OpenLDAP,
exportamos la clave del principal recién creado a un fichero para su uso por parte de PDNS. Esto debe hacerse desde el servidor master, ya que
al realizar la exportación se realiza un modificación en las entradas
correspondientes en OpenLDAP y por tanto es necesario que el KDC realice operaciones de escritura:
 |
| Exportación keytab servidor PDNS1. |
 |
| Exportación keytab servidor PDNS2. |
Una vez que tenemos listos los keytabs de todos los servicios, pasamos a realizar la configuración de los mismos para que se utilice Kerberos como mecanismo de autenticación entre ellos.
Para empezar de forma sencilla, comenzamos con el
servicio PDNS. PDNS permite configurar el tipo de validación a utilizar con el backend LDAP con las siguientes
opciones de configuración:
- ldap-bindmethod, permite especificar las opciones simple, el método básico con un DN y una password o gssapi, para el uso de Kerberos.
- ldap-krb5-keytab, especifica la ruta al fichero que contiene la clave que se usará para la validación.
- ldap-krb5-ccache, especifica la ruta completa al fichero que almacenará la cache de credenciales de Kerberos.
Por tanto, la configuración necesaria del servidor PDNS implica añadir las siguientes lineas al fichero /etc/pdns/pdns.conf:
 |
| Configuración de PDNS para usar Kerberos. |
Como es lógico, utilizaremos el keytab específico para cada servidor en cada caso y es muy importante tener en cuenta los permisos de acceso a dicho fichero si configuramos el servicio para que utilice un usuario diferente a root, que es lo más recomendable.
A continuación, configuramos OpenLDAP para que utilice
el fichero keytab al arrancar, para lo cual es necesario cambiar el fichero de
configuración correspondiente que dependerá de la distribución
utilizada. En este caso tenemos lo siguiente para CentOS y Debian:
 |
Configuración keytab OpenLDAP en CentOS
|
 |
Configuración keytab OpenLDAP en Debian.
|
Al
reiniciar el servicio OpenLDAP este utilizará el keytab especificado.
Como es lógico, es muy importante que tenga los permisos correctos y el propietario del fichero sea el usuario que
ejecuta el servicio slapd.
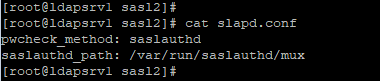
Ahora es necesario que pasemos a configurar OpenLDAP para que soporte mecanismos de validación adicionales. Por tanto, antes
de continuar, comprobemos los mecanismos de autenticación soportados por el servidor OpenLDAP. Para esto basta con realizar una consulta
como la siguiente:
 |
Comprobación de mecanismos SASL soportados.
|
Como
se puede apreciar en la imagen anterior, todavía no hay ninguno disponible, así que tenemos que añadirlos, empezando por el
plugin correspondiente de SASL para GSSAPI ya que todos los mecanismos de autenticación adicionales o externos, como Kerberos en este caso, emplean la biblioteca SASL y los plugins proporcionados por dicha biblioteca. Para instalar el plugin, por ejemplo en CentOS, solo es necesario
hacer lo siguiente:
 |
| Instalación de plugin GSSAPI de SASL. |
Con el plugin instalado, debemos cambiar la configuración existente de la biblioteca SASL para incluir los nuevos mecanismos a utilizar por parte de OpenLDAP.
En una entrada anterior de esta serie, concretamente en
esta, configuramos OpenLDAP para realizar autenticación
passthrough y usar Kerberos para validar usuarios. Como vimos entonces, OpenLDAP utilizaba un servicio de autenticación externo, delegando el proceso de autenticación al proceso saslauthd, para todas aquellas entradas cuyo atributo userPassword tuvieran el formato {SASL}principal@REINO. El contenido del fichero que, por tanto, debemos tener inicialmente es parecido a este:
 |
Configuración SASL para autenticación passthrough.
|
La configuración anterior permite delegar el proceso de autenticación a un servicio externo, pero ahora necesitamos que OpenLDAP soporte otros mecanismos de autenticación, para que clientes puedan acceder usando otros mecanismos de autenticación. Esto requiere que configuremos adecuadamente la biblioteca SASL para OpenLDAP, añadiendo los mecanismos del plugin GSSAPI, lo que permitirá el uso de tickets Kerberos para realizar operaciones de lectura y escritura en el servidor. A partir del fichero anterior, la configuración quedaría del siguiente modo:
 |
Configuración SASL incluyendo mecanismos adicionales.
|
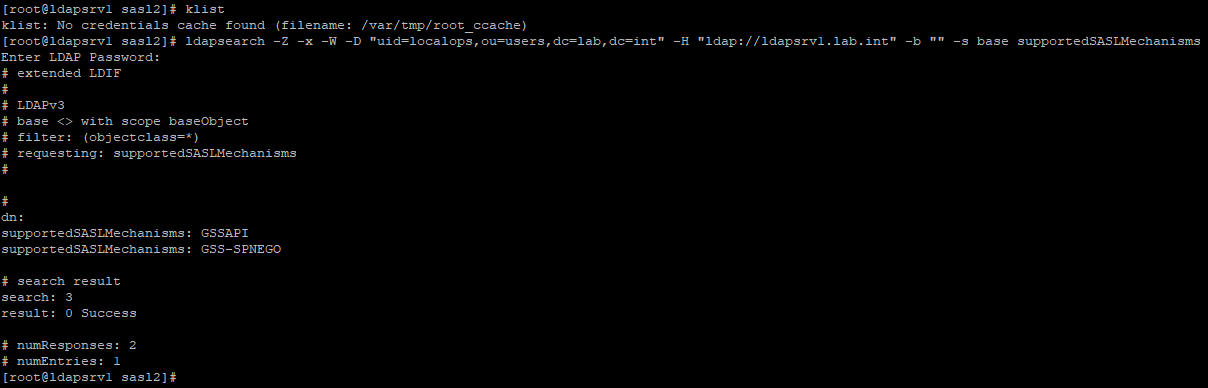
Con esta configuración, y tras reiniciar el servidor OpenLDAP, podemos comprobar que se soportan todos los casos:
 |
Búsqueda usando autenticación GSSAPI.
|
 |
Búsqueda usando autenticación SIMPLE y passthrough.
|
 |
Búsqueda usando autenticación SIMPLE y validación local.
|
Como podemos apreciar en los ejemplos anteriores, hemos realizado una operación de consulta al servidor OpenLDAP con las siguientes características:
- En el primer caso, el usuario que realiza la operación debe obtener un ticket de Kerberos. Usando dicho ticket realiza la consulta al servidor OpenLDAP especificando como mecanismo de autenticación GSSAPI. Este proceso es el mismo que queremos configurar para PDNS.
- En el segundo ejemplo, un usuario realiza una consulta empleando el método de autenticación SIMPLE, es decir, presentando un par DN-contraseña. Como ese usuario tiene delegada la autenticación (atributo userPassword: operator1@LAB.INT), OpenLDAP delega la validación del mismo al proceso saslauthd.
- En el último caso, muy similar al anterior, comprobamos que la validación empleando em método de autenticación SIMPLE con un usuario cuya contraseña se encuentra en el propio servidor OpenLDAP, y que por tanto no se delega a ningún autenticador externo, también puede acceder correctamente al servidor OpenLDAP.
Por tanto, el servidor OpenLDAP ya está configurado para emplear los mecanismos necesarios para su integración con Kerberos y ahora, siguiendo con la configuración del mismo, tenemos que pasar a realizar un mapeo de dichas autenticaciones a DNs existentes. Pero, ¿que es exactamente esto de los mapeos de autenticación a DNs?
Para un servidor OpenLDAP, cualquier operación bind que se realice requiere de un DN. Con esto quiero decir que internamente, una vez que un usuario o una aplicación ha realizado un bind con el servidor OpenLDAP, lo que se espera es tener algo con el formato de un DN, por ejemplo cn=.... o uid=...., que identifique la entidad que ha realizado dicho bind. Esto es así porque, posteriormente existirán ACLs que permitirán o denegarán el acceso a ramas del árbol o a atributos, y las ACLs se basan en la comparación del DN que ha hecho el bind con la especificación de las reglas que las establecen.
Al emplear un procedimiento de autenticación externo, la operación de bind que se realiza con el servidor OpenLDAP no devuelve un DN existente en el servidor, sino algo como lo siguiente:
 |
Bind con autenticación externa.
|
Al realizar una búsuqeda empleando un ticket de Kerberos, cuando la validación es correcta, OpenLDAP construye un DN como el que podemos ver en la imagen anterior. Básicamente el DN indica el reino del ticket Kerberos y el mecanismo de autenticación empleado. Como es lógico, con esta configuración básica podríamos validar entidades externas, como el servicio PDNS, pero para poder aplicar ACLs y controlar a que ramas tiene acceso cada uno de los servicios, lo mejor es convertir dicho DN a uno existente en el árbol de directorio. Es en este paso donde entra el mapeo de DNs, el cual se realiza con la confioguración de reglas de mapeo usando el atributo de configuración dinámica olcAuthzRegexp el cual, empleano expresiones regulares, nos permitirá convertir DNs específicos o conjuntos de los mismos, a otros DNs diferentes.
De forma muy básica, viendo el DN generado con una autenticación GSSAPI, podemos establecer un mapeo de autorizaciones muy simple usando una expresión como la siguiente:
 |
Mapeo simple de autenticación GSSAPI.
|
Al aplicar este atributo en la rama de configuración dinámica y reiniciar el servicio slapd, ahora tenemos lo siguiente al realizar un bind empleando el mecanismo GSSAPI:
 |
Mapeo de DN efectivo.
|
Una vez establecida toda la configuración necesaria, debemos pensar un momento en la secuencia de arranque del servicio PDNS. Al arrancar el servicio, este necesita solicitar un ticket a partir del keytab de servicio que hemos creado y establecido en su configuración. Al hacer esto, debe generar un fichero donde almacenará la caché de credenciales de Kerberos, usada para posteriormente poder realizar peticiones al servidor OpenLDAP. Pues bien, al menos en la version del servidor autoritativo de PowerDNS que estoy utilizando, en concreto la 4.5.1, al arrancar el servicio tras realizar toda la configuración, este no es capaz de iniciarse y se recibe un error que indica que los permisos del fichero de caché de credenciales no son conrrectos:
 |
Error del fichero de caché de credenciales.
|
Tras bastantes pruebas y analizar el arranque con strace, el error se produce sencillamente porque no es capaz de acceder al fichero que contiene la cache, el cual se está generando durante el arranque y antes de que el proceso cambie a ser del usuario pdns. Con la configuración que he establecido, el servicio cambia al usuario pdns al arrancar y según el análisis realizado, intenta acceder al archivo de credenciales que ya es del usuario root, recibiendo el error indicado.
Si arrancamos el proceso manualmente, en vez de lanzar el servicio definido mediante systemctl, se recibe el siguiente error que es bastante más esclarecedor de lo que puede estar sucediendo:
 |
Error de caché de credenciales durante el arranque de PDNS.
|
Este problema se debe, única y exclusivamente, a que el propietario del directorio de instalación de PDNS, que está en /etc, es el usuario root y no el propio usuario pdns. Por tanto, podemos cambiar el propietario de /etc para que sea del usuario pdns, pero es importante tener en cuenta que, quizás la actualización automática del paquete, pueda cambiar de nuevo dichos permisos. Con esta solución, la configuración de pdns quedaría del siguiente modo:
 |
| Configuración corregida de PDNS. Fichero /etc/pdns/pdns.conf. |
Es muy importante asegurar que, en el fichero de descripción del servicio, no esta incluida la opción ProtectSystem=full, ya que esta evita que el proceso escriba en /etc con lo que es necesario cambiarla a false en caso de estar presente. Esto puede incluir que, al para el servicio usando systemctl, dicho fichero de caché de credenciales no se elimine, lo cual provocará un fallo en el siguiente arranque del servicio, con lo que es necesario modificar la descripción del servicio para borrar dicho fichero. Como referencia, una posible solución a estos problemas sería similar a la siguiente:
 |
Modificaciones de la descripción del servicio pdns.
|
Con toda esta configuración, ya podemos arrancar el servicio pdns el cual, se valida usando Kerberos para poder realizar operaciones de lectura con el servidor OpenLDAP:
 |
Servicio pdns arrancado.
|
Hasta aquí esta entrada y en cuanto saque otro rato, seguiremos integrando servicios con Kerberos para poder asegurar más nuestras infraestructuras.