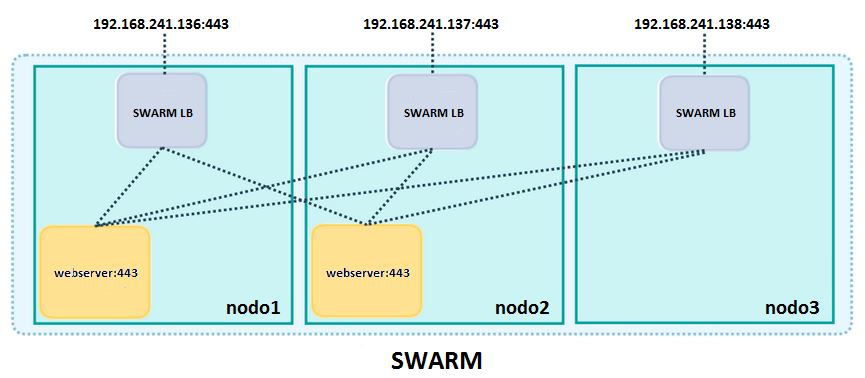
Hoy, tras los dos entradas anteriores sobre Docker swarm, es buena idea que le demos un repaso a los comandos básicos de los que disponemos cuando estamos interactuando con un cluster de Docker swarm. Como vamos a ver, son muy similares a los que hemos estado utilizando en el caso de un dockerhost y nos permiten realizar las mismas tareas, con la única diferencia de que ahora se realizarán y afectarán a todos los hosts que forman nuestro swarm.
Lo primero a tener en cuenta es que los comandos debemos realizarlos desde un nodo manager del swarm, ya que son los nodos que coordinan las tareas de los nodos worker del cluster. De forma simple podemos consultar el rol de cada uno de los nodos del swarm con el comando docker node ls:
 |
| Nodos de un swarm y su rol. |
Como vemos, la columna manager status, nos muestra que el nodo swarm-node1 es un nodo manager y por tanto desde este nodo ejecutaremos todos los comandos de administración del swarm. Como referencia, en general siempre será un nodo manager aquel en el que ejecutamos el comando docker swarm init para crear el swarm inicialmente.
Al ejecutar un comando de control de swarm en un nodo worker del mismo, recibiremos un mensaje de error como el siguiente:
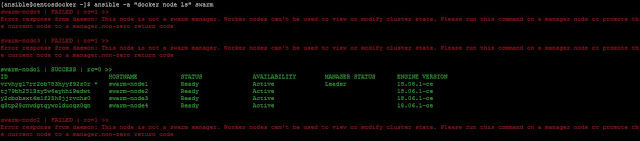 |
| Mensajes de error de nodos worker al ejecutar comandos swarm. |
Con el comando docker node, podemos actuar sobre los nodos del swarm y realizar diferentes tareas sobre ellos. Por ejemplo podemos promover un nodo worker a manager usando el comando docker swarm promote, por ejemplo:
 |
| Convertimos un nodo worker en manager. |
Con lo que ahora, el ejecutar de nuevo el comando docker node ls, la salida será la siguiente:
 |
| El swarm con un nodo manager adicional. |
Paremos un momento para analizar la salida de este comando. Como vemos hay varias columnas con información sobre cada uno de los nodos del swarm, siendo las más importantes las columnas Status, Availability y Manager Status, siendo su significado el siguiente:
- Columna Status, nos muestra el estado del nodo. Como es lógico esta columna nos indica si el nodo en cuestión está operativo y es alcanzable. Los estados posibles son Ready o Down.
- Columna Availability. Esta columna nos indica si el nodo está disponible para recibir y ejecutar tareas. Un nodo que forma parte de un swarm puede estar en tres estados de disponibilidad:
- Active, el nodo puede ejecutar tareas y recibir tareas nuevas.
- Pause, el nodo no puede recibir tareas nuevas pero, aquellas tareas ya asignadas al mismo siguen ejecutándose.
- Drain, el no nodo no puede recibir tareas nuevas y, aquellas tareas ya asignadas al mismo se detienen y se asignan a otro nodo.
- Columna Manager Status. Esta columna nos muestras que nodos del swarm son nodos manager y de ellos cual es el nodo manger primario, indicado como Leader y todos los nodos manager secundarios se indican como Reachable.
Como es lógico siempre es buena idea tener más de un nodo manager en cualquier swarm ya que, de se modo, si el manager primario pasa a estar no disponible, cualquiera del resto de nodos manager secundarios, pasará a ser el nuevo manager primario que realizará las tareas de orquestación y asignación de tareas del swarm.
Del mismo modo que podemos promover un nodo worker a nodo manager con el comando docker node promote, también podemos despromocionarlo con el comando docker node demote.
Como ya vimos en una entrada anterior, que un nodo tenga el rol manager no implica que no se ejecuten contenedores en el mismo. Si repetimos el despliegue del servicio web simple que realizamos en una entrada anterior, cambiando un poco los parámetros veremos como se distribuyen los contenedores en todos nuestrios nodos del swarm:
 |
| Creamos un servicio con 4 replicas. |
Al inspeccionar donde están corriendo las réplicas de este servicio, veremos como ha desplegado el nodo manager las tareas:
 |
| Información sobre las réplicas del servicio en el swarm. |
En este caso comprobamos que el nodo manager primario ha distribuido una réplica en cada uno de los nodos del swarm y por tanto, podemos acceder al servicio desde cada uno de los nodos de manera individual.
Ahora supongamos que necesitamos aumentar el número de réplicas de nuestro servicio porque, con las réplicas con las que inicialmente lo hemos desplegado, no es suficiente para el número de peticiones de nuestros clientes. Para estos casos usaremos el comando docker scale, el cual nos permite levantar réplicas adicionales de un servicio ya desplegado de una manera muy rápida y sin ningún corte en el servicio actual. Por ejemplo, pasemos nuestro servicio de 4 réplicas a 10:
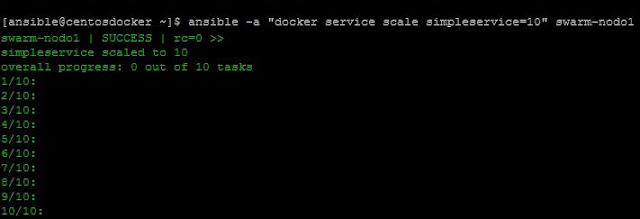 |
| Escalado del servicio a 10 réplicas. |
Ahora, al comprobar el número de contenedores de este servicio usando el comando docker service ps, vemos que tenemos desplegados 10 contenedores entre todos los nodos del swarm:
 |
| Listamos las réplicas del servicio tras el escalado. |
|
Del mismo modo, podemos escalar el servicio disminuyendo el número de réplicas del siguiente modo:
 |
| Reducción del número de réplicas de un servicio. | | | | |
Por último, si queremos parar el servicio lo que tenemos que hacerlo es eliminarlo con el comando docker service rm:
 |
| Eliminación del servicio en el swarm. |
En resumen hemos visto cómo administrar un swarm es muy similar a la administración de un dockerhost individual, como los comandos utilizados en swarm son muy parecidos a los utilizados con un dockerhost y sobre todo, hemos podido comprobar la potencia que nos proporciona para escalar servicios en caso de ser necesario de forma muy rápida y simple.
En las próximas entradas revisaremos los tipos de despliegue de servicios y veremos como montar volúmenes para conseguir persistencia en nuestros servicios.