Hoy, en esta nueva entrada sobre Kubernetes, vamos a comenzar el estudio de los objetos básicos existentes en la API de Kubernetes. Estos objetos son representaciones del estado que queremos o necesitamos del cluster con el que controlaremos que cargas queremos desplegar y como desplegarlas.
Vamos a empezar con los dos objetos fundamentales sobre los que se construyen otros objetos más complejos. Estos objetos son:
- Pod. Un pod es la encapsulación de un contenedor en Kubernetes y es la unidad básica de ejecución disponible.
- Service. Es un recurso dentro de un cluster de Kubernetes que me permite exponer un pod al exterior, permitiendo así el acceso al mismo.
Como este resumen es demasiado simple, veamos cada uno de estos objetos con más detalle.
Kubernetes es un sistema de orquestación de contenedores y uno de los requistios necesarios para su instalación es disponer de un motor de ejecución de contenedores como Docker. Ahora bien, aunque Kubernetes utilizará Docker para ejecutar contenedores, estos debemos configurarlos siguiendo la representación que veremos en otro post de esta serie sobre los conceptos básicos de Kubernetes. De esta manera, Kubernetes será capaz de controlar dichos contenedores y establecer el estado del sistema al estado deseado por nosotros. La representación de un objeto de Kubernetes debe seguir el siguiente formato:
 |
| Spec de un objeto de Kubernetes. |
En el caso de querer definir un pod, la especificación del mismo sería algo como lo siguiente:
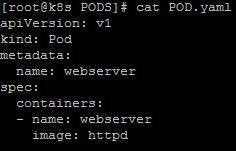 |
| Especificación de un POD básico. |
Analizando la definición anterior, podemos ver la encapsulación a la que me refería al definir un pod. En este caso tenemos los campos necesarios en los que establecemos que versión de API queremos utilizar, que el tipo de objeto es Pod, en metadata definimos el nombre de nuestro pod y, en la sección spec, establecemos que queremos un contenedor que debe ejecutar la imgen oficial del servidor http de Apache. En esta especificación vemos como objetos diferentes, en este caso el objeto pod y el objeto containers, pueden tener el mismo nombre.
Cada objeto disponible en la API de Kubernetes dispone de múltiples opciones para su especificación y es importante consultarla para definir correctamente nuestros objetos. En el caso del objeto pod, la referencia en el API de Kubernetes para la versión 1.17 podéis encontrarla aquí.
Lo habitual es que no interactuemos directamente con pods, sino que utilicemos objetos superiores que nos darán otras funcionalidades de las que el objeto pod carece, pero para empezar desde lo más simple creemos nuestro primer pod usando la configuración anterior. Para esto solo tenemos que usar el comando kubectl y aplicar dicho fichero con la especificación del objeto:
 |
| Creación de un pod simple. |
Si queremos listar todos los pods que están ejecutándose en el cluster solo tenemos que emplear el comando siguiente:
 |
| Lista de pods en el cluster. |
He indicado que un pod es una encapsulación de un contenedor básico con la información necesaria para que Kubernetes pueda controlarlo. Al utilizar Docker como motor de contenedores, podemos entender mejor esta encapsulación listando los contenedores que se están ejecutando en el sistema:
 |
| Lista de contenedores ejecutándose en el sistema. |
Como podemos ver, hay dos contenedores relacionados con el pod que acabamos de crear. Uno de ellos ejecuta la imagen httpd que hemos especificado en el fichero de definición de nuestro pod y el otro una imagen propia de Kubernetes.
Podemos comprobar mejor esta relación si creamos un nuevo pod en el cual definimos nombres diferentes para el pod y el contenedor. Por ejemplo, si definimos un nuevo pod con la siguiente especificación y lo aplicamos:
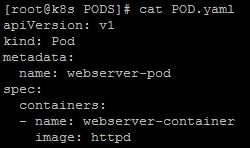 |
| Definición de un pod simple. |
 |
| Contenedores relacionados con el pod creado. |
Por tanto, con esto ejemplo, vemos como definimos un objeto básico y la relación que hay entre Kubernetes y el motor de contenedores que se ejecuta en los nodos que forman nuestro cluster.
Ahora que hemos creado dos pods que ejecutan una imagen del servidor web de Apache, tenemos que publicar dicho servicio al exterior del cluster ya que, por defecto, los pods solo son accesibles por otros pods. Para esto definiremos otro objeto de Kubernetes que se denomina service, la definición básica que podemos usar para este tipo de objeto sería:
 |
| Definición básica de un objeto service. |
De nuevo, recordando el formato de especificación que debemos seguir con todos los objetos de Kubernetes, observamos los campos requeridos, siendo en este caso el tipo Service y dentro de la especificación del tipo de objeto tenemos los siguientes elementos:
- El campo selector me permite definir una serie de etiquetas con las que especificar a que pods vamos a aplicar este service.
- El type Nodeport indica a Kubernetes que debe publicarse el servicio en todos los nodos del cluster en el puerto público indicado por nodePort. El puerto del pod al que deben enrutarse las peticiones de los clientes está dado por port.
Por tanto, lo que estamos fijando es que el puerto 80 de los pods que tengan la etiqueta source: webserver, se publicarán al exterior a través del puerto 30080 de cada nodo del cluster. Al aplicar esta definición de servicio al cluster pasamos a tener lo siguiente:
 |
| Aplicamos el servicio y listamos los objectos existentes. |
Como podemos ver tenemos los dos pods iniciales y dos servicios, siendo uno de ellos propio de Kubernetes y del cual, por el momento, no vamos a preocuparnos.
Si obtenemos la descripción del servicio que acabamos de crear, veremos la siguiente salida:
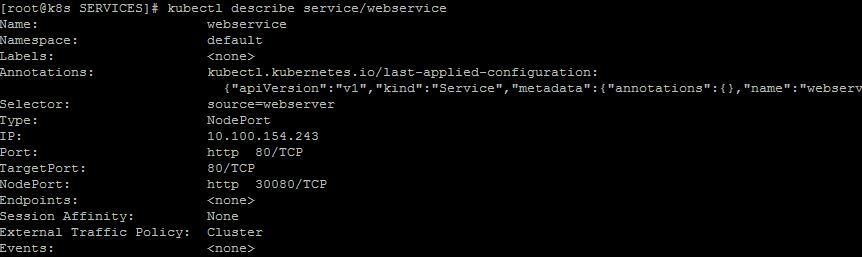 |
| Descripción del servicio webservice. |
A partir de nuestra especificación podemos ver que la dirección IP interna asignada al servicio es la 10.100.154.243, que el puerto en los nodos es el 30080 y que el puerto target, o puerto en los pods, es el puerto 80 pero, además, vemos que el campo Endpoints está vacio.
Fijándonos en el campo Selector de nuestra definición, hemos establecido que este servicio debe publicar el puerto 80 de aquellos pods que contengan la etiqueta source=webserver. Cómo no hemos creado los pods con dicha etiqueta, ahora mismo este servicio está escuchando en el puerto 30080 de nuestros nodos pero no hay un pod que reciba las peticiones, con lo que no podremos conectarnos.
Para poder conectar este servicio con un pod que ejecute nuestro servidor web, tenemos que modificar la especificación del mismo y añadir una etiqueta al pod que coincida con el selector especificado en el servicio. Ahora nuestro pod quedaría del siguiente modo:
 |
| Añadimos la etiqueta a la especificación del pod. |
Borramos los pods creados anteriormente y aplicamos la nueva definición de pod, con lo que ahora tenemos lo siguiente:
 |
| Creamos el nuevo pod. |
Ahora, al obtener de nuevo la descripción del objeto service/webservice vemos una diferencia en el campo Endpoints:
 |
| El objeto service con el endpoint del nuevo pod. |
Como ya hemos dicho, el KCP comprueba continuamente que el estado del cluster es idéntico al que hayamos establecido por configuración. Esto nos permite, para algunos objetos, hacer cambios de su configuración en caliente. De este modo podemos cambiar la definición de un objeto y volver a aplicarla mientras el objeto está corriendo sin necesidad de eliminar dicho objeto. Esta idea aplica al cambio que acabamos de realizar sobre la definición de los PODs. Podemos cambiar la definición del POD, añadiendo las etiquetas que necesitemos y aplicar la nueva configuración a los PODs que estén ejecutándose, con lo que el resultado sería el mismo, pero evitamos borrar los PODs.
Con lo que ahora, si podremos conectarnos usando un navegador web:
 |
| Conexión con nuestro cluster de Kubernetes. |
Una de las conclusiones que podemos obtener de este ejemplo es que, una vez creado un servicio, Kubernetes está comprobando de forma continua si hay endpoints disponibles para el mismo. Como hemos visto, una vez que existe un pod con la etiqueta correcta, Kubernetes enlaza el servicio que hemos definido con dicho pod permitiendo el acceso desde el exterior del cluster.
Al igual que con la definición del objeto pod, en este enlace podemos consultar la entrada correspondiente al objeto service del API de Kubernetes.
En resumen, hemos visto cómo definir los objetos pod y service así como la flexibilidad que tiene el separar ambos objetos. Además hemos comprobado la relación entre un pod y un contenedor y hemos visto cómo Kubernetes aplica el estado que fijamos por configuración, relacionando un servicio con un pod cuando la etiqueta del pod coincide con el campo selector del servicio.