Hola de nuevo, hoy toca una entrada sobre backup, en concreto sobre NetWorker y los cambios introducidos en las versiones 9.x.
Acabamos de terminar la migración de nuestro servicio de backup en versión 8.4.2, a la reciente versión 9.2.2 y he aprovechado para realizar cambios en la infraestructura. El cambio más importante ha sido la virtualización del servidor de backup, con lo que he separado el nodo de almacenamiento que controla la biblioteca de cintas del propio servidor.
El proceso de actualización ha implicado un cambio de plataforma, lo que Dell/EMC denomina una migración cruzada, ya que nuestro servidor de backup era un sistema Solaris 10 y el nuevo servidor es un servidor virtual Red Hat 7. Este tipo de migración solo está soportado si lo realiza personal de Dell/EMC así que, con su ayuda, hemos hecho la migración en aproximadamente 3 días.
Durante la instalación del servidor ya encontramos varios cambios, siendo los principales que es necesario instalar el servidor de autenticación y el servidor de licencias. Por tanto, si monitorizamos los procesos del servidor, ahora tendremos que incluir el servidor flex y los procesos asociados al servidor de autenticación en nuestro sistema de monitorización.
Otros de los cambios más importantes es la propia base de datos de NetWorker la cual, basada antes en WiSS, es ahora una base de datos SQLite, lo cual introduce muchas mejoras de rendimiento en el funcionamiento del servidor.
Pero los cambios de verdad los vemos al entrar en la NMC ya que ahora, la nueva consola presenta el siguiente aspecto:
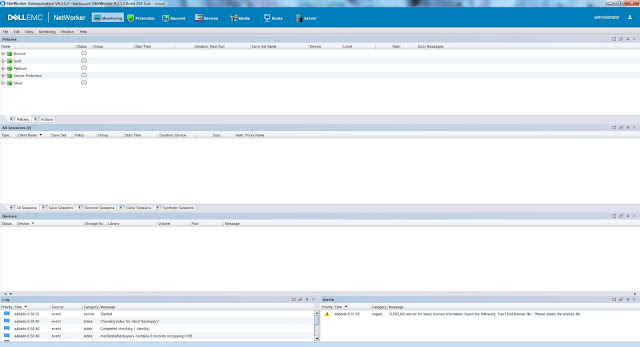 |
| Consola de adminsitración de NetWorker 9.2. |
A primera vista es muy similar a la de las versiones 8.x y practicamente tenemos las mismas secciones, salvo por la sección Protection que es donde nos vamos a encontrar el cambio fundamental en como NetWorker nos permitirá proteger nuestra información.
En la sección Protection nos encontramos con la siguiente estructura:
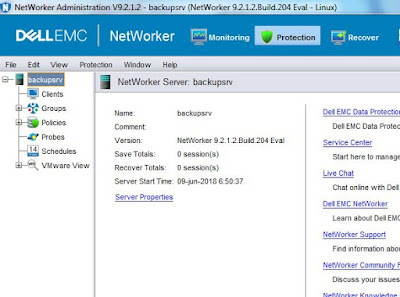 |
| Sección Protection de NMC. |
Hay varios apartados que nos resultarán familiares de las versiones anteriores menos el apartado Policies, dentro del cual veremos que es donde se centra el cambio en como definimos nuestra estrategia de protección de datos.
Para ver las diferencias vamos a crear un cliente de backup usando el asistente de creación de nuevo cliente, que es el método recomendado de creación. Una vez terminado veremos nuestro nuevo cliente en la consola con una marca, la cual nos indica que el cliente no forma parte de ninguna política de protección.
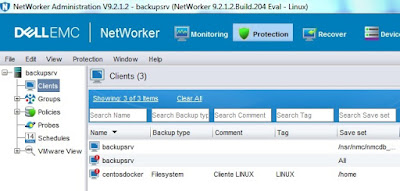 |
| Lista de clientes de backup disponibles. |
A continuación creamos un grupo de clientes de backup en el que vamos a incluir nuestro nuevo cliente:
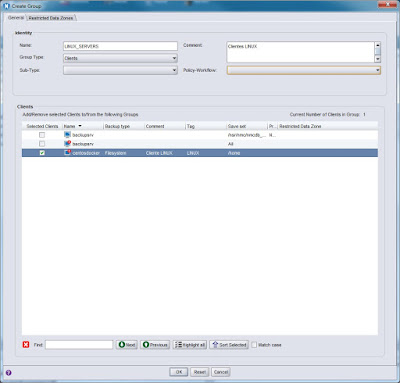 |
| Creación de un nuevo grupo de backup. |
Mientras que en versiones anteriores de NetWorker teníamos muchas opciones cuando configurábamos un grupo, ahora queda claro que un grupo de backup o protección es un conjunto de clientes organizado siguiendo el citerio que queramos fijar. En versiones anteriores recuerdo que olvidaba asignar el grupo al pool de cintas que quería usar para el backup de dicho grupo y, cuando se lanzaba el backup, el servidor siempre pedía una cinta del pool Default para poder realizar el backup. Ahora ya no hay una relación directa entre un grupo de backup y el pool de cintas a utilizar, con lo que veremos un poco más adelante como establecemos dicha relación.
Por tanto hasta ahora, en lo que respecta a la configuración de los clientes no encontramos muchas diferencias, pero en cuanto a los grupos de clientes no hemos configurado el pool a utilizar, si el grupo y el autostart están habilitados, el schedule, si queremos guardar los índices, etc...
El siguiente punto es la creación de una política, a partir de la cual podremos empezar a definir cómo queremos proteger nuestros datos. La creación de una política es tan sencillo como:
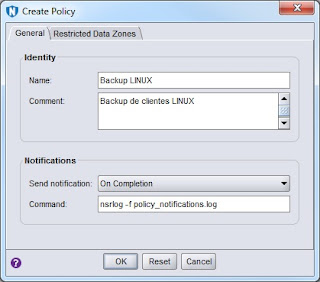 |
| Creación de una nueva política. |
Como podemos ver, lo único configurable es el nombre, comentario y tipo de notificación que se generará. Así que ¿como establezco la política de protección del grupo que acabo de crear? Creando un workflow que contendrá una o más acciones que queremos realizar sobre el grupo de protección.
Desde la política que acabamos de crear crearemos un workflow del siguiente modo:
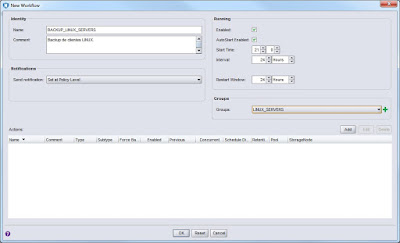 |
| Nuevo workflow de protección de clientes. |
Ahora, dentro del workflow, definimos las acciones que queremos realizar y que se aplicarán solamente sobre el grupo LINUX_SERVERS que hemos definido antes.
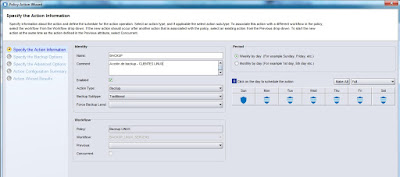 |
| Creación de una acción de backup - Tipo de backup y programación. |
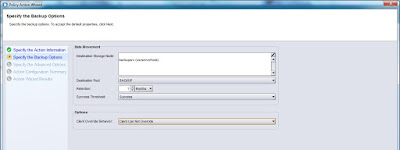 |
| Creación de una acción de backup - Retención y pool. |
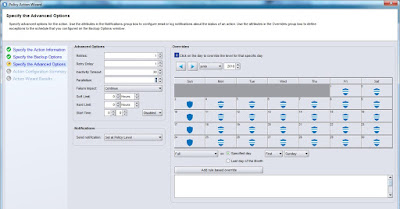 |
| Creación de una acción de backup - Opciones avanzadas y cambios en programación |
|
Ahora que hemos definido la acción de backup sobre el grupo podemos resumir lo siguiente:
- Los clientes se organizan en grupos de protección. Estos grupos los crearemos según nuestros propios criterios, pero no disponen de más información que los clientes que los forman y el nombre del grupo.
- Las políticas de backup, también creadas según nuestros criterios y entorno, contendrán los workflows que aplicaremos a los grupos de protección anteriores. El workflow ya me permite configurar la hora de inicio, el intervalo y contiene las accioens que realizaremos sobre los grupos de protección.
- La acción o acciones que contenidas en un workflow me permitirán definir la programación, el storage node, el pool, la retención y cualquier opción adicional necesaria.
Una vez terminada la configuración, nuestro workflow se representará graficamente del siguiente modo:
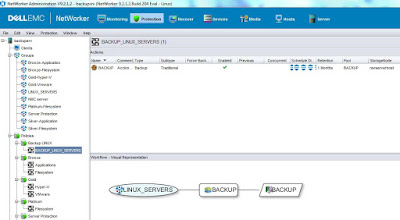 |
| Representación gráfica de un workflow de backup. |
Con esta representacion gráfica queda claro que, sobre el grupo de protección LINUX_SERVERS vamos a realizar una acción de backup y que el pool a utilizar se llama BACKUP.
Todos estos cambios ya estarán reflejados en la sección Monitoring, desde la que podremos lanzar un backup de nuestro grupo con solo ejecutar el workflow correspondiente:
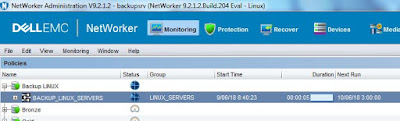 |
| Ejecución de un workflow de backup. |
Una vez terminado el backup, podremos consultar los logs y resultado del mismo desde esta sección:
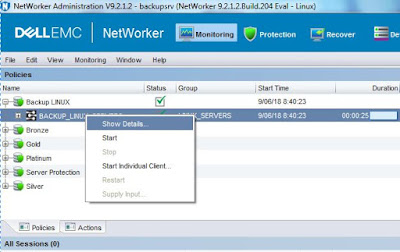 |
| Consultando el resultado de un backup. |
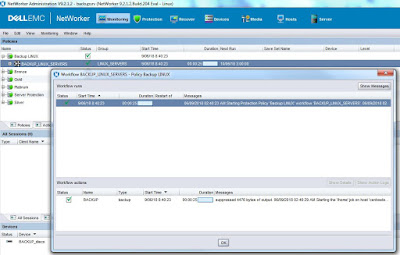 |
| Resultado y logs de un backup. |
Así que hasta aquí, para todos los que administramos NetWorker, las diferencias fundamentales se basan en la relación entre todos los elementos que nos permiten diseñar nuestra estrategia de backup.
Después de tantos años trabajando con NetWorker, desde la version 7.x, creo que el cambio le hacía falta y que el resultado es un sistema mucho más moderno tanto desde el punto de vista funcional como operativo, sin contar todos los cambios realizados en el código y todas las funcionalidades añadidas.
Como todavía me falta mucho por leer, en breve intentaré hacer otra entrada con más información sobre esta nueva versión de NetWorker.