Como ya comenté en la entrada sobre acceso multiprotocolo, hay un concepto asociado a los accesos CIFS que es fundamental y que es muy importante comprender.
Siempre que un sistema cliente Windows accede a una carpeta compartida por CIFS, independientemente de si es un sistema NetApp 7-mode o C-mode, se realiza un mapeo de usuarios de Windows a Unix.
Esto se explica teniendo en cuenta los orígenes de los sistemas NetApp como servidores NFS y que están basados en FreeBSD.
Puede que no sea muy intuitivo pero, aunque no estemos hablando de acceso multiprotocolo este mapeo de usuarios siempre es necesario y en caso de que no se realice correctamente, se denegará el acceso al share.
Vamos a ver esto resumido con unos cuantos ejemplos empezando con una SVM que solo proporcione acceso CIFS. Este caso, que es el más simple, nos permite ver las opciones existentes para mapear usuarios.
Cuando creamos una SVM con protocolo CIFS, la unimos a un dominio y creamos un share CIFS, cuando nos conectamos y consultamos las sesiones CIFS veremos lo siguiente:
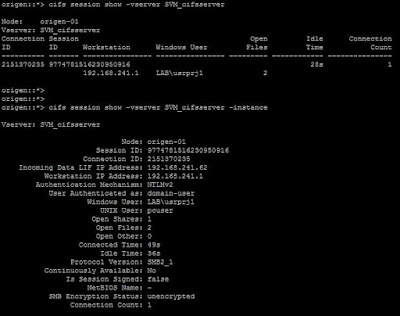 |
| Sesiones CIFS existentes en una SVM. |
En la salida anterior vemos que nuestro usuario del dominio, se ha mapeado al usuario Unix pcuser. La pregunta evidente es de donde sale ese usuario y como se ha establecido dicho mapeo.
Si analizamos la configuración del servidor CIFS de nuestra SVM, usando el comando cifs options show, veremos un montón de opciones de configuración y entre ellas, la siguiente:
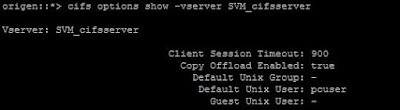 |
| Opciones de configuración del servidor CIFS de una SVM. |
Esa opción denominada Default Unix User, es la que establece que usuario se usará por defecto para mapear cualquier usuario Windows que se conecte a este servidor CIFS, sino hay otro método establecido de mapeo. En ONTAP 7-mode el equivalente es usar el comando options con la opción de configuración wafl.default_unix_user la cual, por defecto, también es pcuser.
Lo que nos queda es saber de donde sale ese usurio, para lo cual, solo tenemos que revisar los usuarios de la SVM desde la sección SVM Settings:
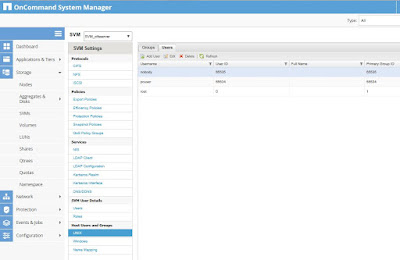 |
| Usuarios Unix locales de una SVM. |
Por tanto, como podemos ver, una SVM tendrá un conjunto de usuarios Unix por defecto, entre ellos el usuario pcuser que se usará por defecto para mapear a cualqueir usuario Windows que se conecte a una carpeta compartida mediante CIFS.
Como vemos hay un apartado Name Mapping desde el cual podemos crear nuestras propias reglas de mapeo en caso de ser necesario. Hagamos una prueba y creemos una regla de mapeo según la cual para determinados usuarios del dominio vamos a usar un usuario Unix local de la SVM diferente. Para esto creamos un par de usuarios Unix nuevos en la SVM, que llamaremos proyecto1 y proyecto2:
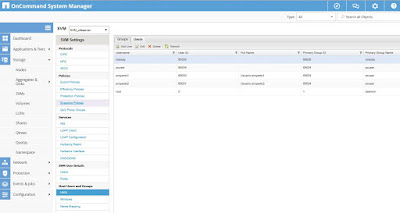 |
| Creamos dos nuevos usuarios locales Unix en la SVM. |
Y ahora establecemos reglas de mapeo específicas para los usuarios del dominio usrprj1 y usrprj2, para esto solo necesitamos crear las reglas en el apartado Name Mapping desde SVM Settings, las cuales serán:
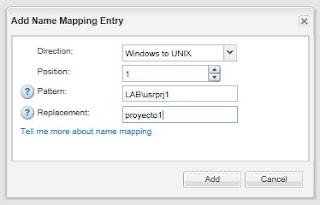 |
| Regla de mapeo para un usuario de Windows a Unix. |
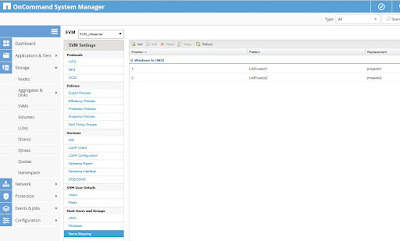 |
| Reglas de mapeo de Win a Unix establecidas para dos usuarios del dominio. |
Con estas dos reglas creadas, al conectarnos de nuevo a la carpeta compartida por CIFS tendremos el siguiente resultado:
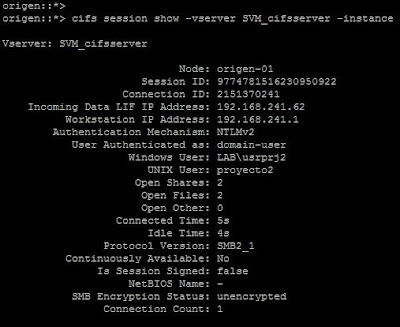 |
| Sesión CIFS establecida para un usuario con mapeo específico. |
Si nos conectamos a esa misma carpeta compartida con un usuario que no tenga ninguna regla de mapeo específica, lo que tendremos será lo siguiente:
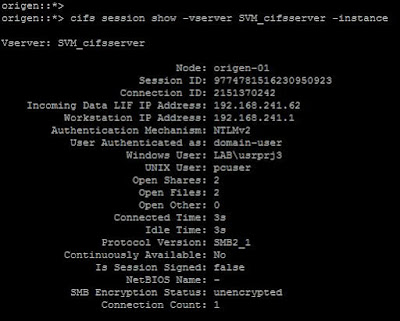 |
| Conexión de un usuario con mapeo por defecto. |
Con lo que, evidentemente se utiliza el uusario pcuser por defecto para realizar el mapeo del usuario Windows que realiza la conexión.
El hecho de que se especifique un usuario Unix para el mapeo es muy importante en el caso de acceso multiprotocolo como vimos en la entrada anterior, ya que los permisos del sistema de archivos en una SVM multiprotocolo deberían ser Unix, mientras que en una SVM CIFS como la de nuestro ejemplo, el sistema de archivos que debemos usar en nuestra SVM debe ser NTFS.
Es decir, lo recomendado cuando tengamos que crear una SVM a la que solo accederán clientes Windos mediante protocolo CIFS, es que la seguridad del sistema de archivos sea NTFS y que dejemos las opciones de mapeo de usuarios por defecto. De este modo no tendremos ningún problema de acceso ni permisos ya que, como podemos ver, el sistema de archivos de la SVM establece perfectamente los permisos según los usuarios del dominio e independientemente de los mapeos de los usuarios:
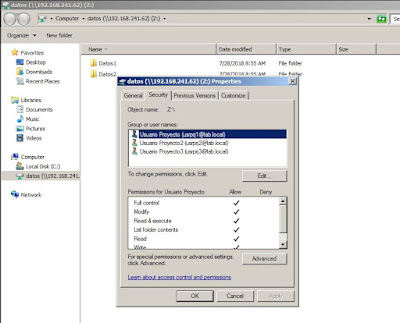 |
| Permisos NTFS en el share de la SVM. |
Al pasar a un entorno multiprotocolo, como el explicado en el post anterior, la cosa se complica un poco más ya que, como vimos, clientes CIFS y NFS accederán a la misma información, en ocasiones simultáneamente. Como un acceso CIFS desde un cliente Windows siempre requiere un mapeo
correcto de usuario, el mapeo
debe realizarse a un usuario Unix válido conocido por los sistemas
cliente Unix o Linux que accederán a la misma información mediante el
protocolo NFS.
Esto nos lleva a que la SVM debe usar como servicio de nombres el mismo que usen nuestros clientes NFS, ya que dicho servicio debe contener todos los usuarios válidos y al mismo tiempo, nos debe permitir realizar el mapeo entre clientes Windows y Unix.
Para estos entornos, lo recomendado es disponer de un dominio Windows, al que uniremos nuestra SVM y que además usaremos de servicio de nombres para nuestras máquinas cliente Unix o Linux así como para nuestra SVM. Hay más opciones disponibles, como usar un servidor OpenLDAP como servicio de nombres implementando el esquema LDAP correspondiente a la RFC 2307 para nuestros sistemas Unix y AD para los sistemas Windows, pero creo que lo más sencillo es disponer de una sola fuente de nombres basada en AD.
Entre los muchos atributos de las entradas de grupos y cuentas de usuario de AD, hay una serie de atributos correspondientes a la RFC 2307 que, mediante la correcta configuración del servicio de nombres de los clientes Unix y Linux y de nuestras SVMs, podremos usar para obtener información de usuarios y grupos, además de poder realizar el mapeo de usuarios del que estamos hablando.
Veamos algunos de esos atributos directamente en las cuentas de usuario de nuestro laboratorio de pruebas:
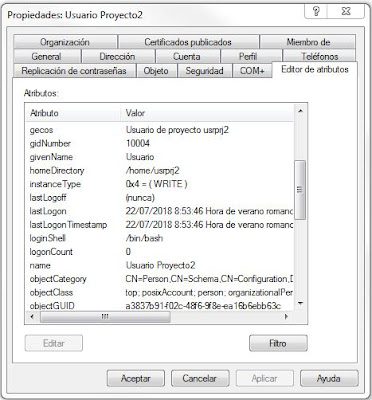 |
| Editor de atributos de una cuenta de usuario. |
Como vemos, hay una serie de atributos que contienen valores que definen una cuenta de usuario de un sistema Unix o Linux, como homeDirectory, loginShell o gidNumber, así como la definición de la clase de objeto posixAccount. En concreto la lista de atributos y clases de objeto está definida en la RFC 2307 y es recomendable su consulta para implementar un servidor LDAP como servicio de nombres para máquinas Unix o Linux.
En el caso de nuestras SVMs, debemos configurarlas para que usen como servicio de nombres de grupos y cuentas de usuario un servidor LDAP, para lo cual solo tenemos que utilizar los siguientes comandos:
 |
| Configuración del cliente LDAP de una SVM. |
 |
| Configuración servicio de nombres de una SVM para que use LDAP para usuarios y grupos. |
De este modo estamos configurando el cliente LDAP de la SVM para que busque la información de grupos y nombres en un servidor LDAP, indicando el DN para realizar las búsquedas, así como el dominio de AD existente, las bases de búsuqeda para cuentas de usuario y de grupo así como el ámbito de las búsquedas.
Con esta configuración establecida, al conectar mediante el protocolo CIFS a nuestra SVM multiprotocolo ya vimos que el mapeo se realizaba correctamente y que al escribir o crear datos, los permisos eran los del usuario mapeado:
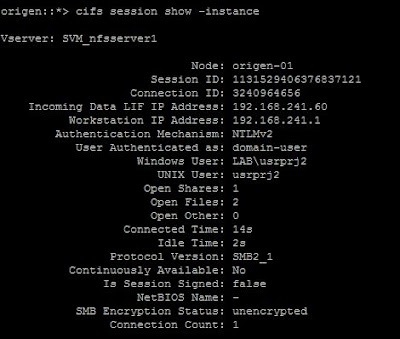 |
| Mapeo correcto de usuario Windows a usuario Unix. |
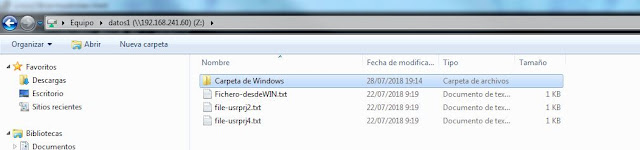 |
| Creación de una carpeta en el share. |
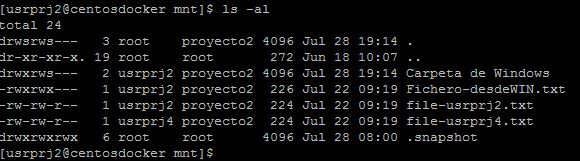 |
| Comprobamos que la carpeta se ha creado con el usuario Unix mapeado correcto. |
Por tanto, si queremos usar SVMs en entornos multiprotocolo, lo recomendado es configurar nuestro servicio de nombres para que use nuestros DCs como fuente de nombres, tanto para los clientes Unix y Linux como para las SVMs. De este modo solo tendremos un servicio de nombres y, el principal problema será la modificación de forma correcta de los atributos correspondientes en AD, pero para esto solo hace falta un poco de Perl o Python y una pequeña web que nos deje modificarlos de forma simple o bien implementarlo en el proceso de alta de usuarios con scripts PowerShell.










































