Siguiendo con Jenkins y su integración con Docker, vamos a estudiar como podemos usar contenedores para realizar builds de nuestros desarrollos, de tal modo que lancemos contenedores efímeros que solo se encargarán de realizar las builds y las pruebas que configuremos para cada caso.
Para poder integrar un servicio Jenkins con un host Docker es necesario configurar el demonio dockerd de nuestro dockerhost para que pueda recibir peticiones por red. Para esto, suponiendo que el servicio Jenkins es un contenedor dentro del propio host Docker, tenemos que editar la configuración del demonio dockerd y añadir una definición de URL para el arranque del demonio. Esto podemos hacerlo de manera simple con el comando systemctl edit docker.service y solo tenemos que añadir las siguientes líneas de configuración:
 |
| Modificación de configuración del servicio Docker para añadir un socket de escucha de red y verificación TLS. |
Una vez realizado este cambio es necesario reiniciar el servicio Docker para que los nuevos cambios tengan efecto, para esto solo es necesario ejecutar el comando systemctl con la opción restart y si todo está correcto, el demonio Docker estará escuchando en el puerto definido en nuestra nueva configuración y requerirá validación TLS. Adicionalmente es muy posible que haya que añadir una regla en los cortafuegos implicados para permitir las conexiones a dicho puerto.
Tras realizar la configuración anterior, pasamos a configurar nuestro servicio Jenkins, con lo que desde el apartado Nube de la configuración del sistema, añadimos un proveedor específico de nube en Jenkins que será de tipo Docker. Para esto, al añadir Docker como proveedor de nube, tendremos que rellenar los campos siguientes:
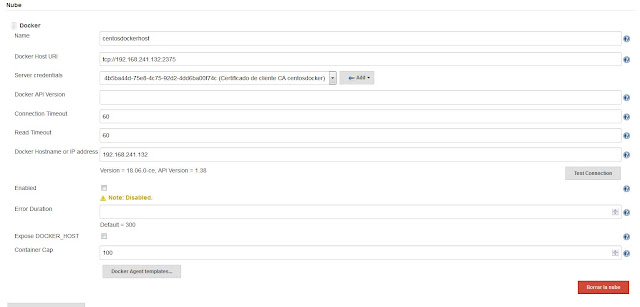 |
| Configuración de nube Docker en Jenkins. |
Es muy importante crear unas credenciales basadas en un certificado para la validación del servicio Jenkins con el demonio dockerd del host remoto. Para esto tendremos que generar un certificado firmado por la misma CA que hemos utilizado para el certificado usado por el demonio dockerd y que hemos especificado en la configuración del servicio Docker del host remoto.
Podemos comprobar que la configuración y el acceso al host Docker es correcto con solo utilizar el botón Test Connection, si todo es correcto la versión del host Docker aparecerá como puede verse en la imagen anterior.
Ahora que hemos realizado la configuración correctamente, podemos ver que nuestro host Docker aparece en el apartado Docker dentro de la configuración de Jenkins:
 |
| Nuestro host Docker registrado en Jenkins. |
El siguiente paso es configurar las imágenes que se usarán para realizar las builds, así como los parámetros que se usarán al lanzarlas. Para esto es importante tener en cuenta que la imagen a utilizar debe tener instalado java, además de las herramientas para realizar la build y pruebas necesarias. Para esto lo recomendable sería crear imágenes a medida, a partir de una imagen base que podemos crear como nodo slave básico de Jenkins. Luego podremos modificar dicha imagen base con las herramientas necesarias para cada uno de los casos que necesitemos.
Para esto lo mejor será, a partir de nuestra imagen base Linux, crear una nueva imagen en la que incluyamos java y git para, posteriormente, crear imágenes en las que incluyamos las herramientas que necesitemos en función de las herramientas de desarrollo que vayamos a utilizar.
Por tanto, para comenzar, creamos una nueva imagen cuyo dockerfile será el siguiente:
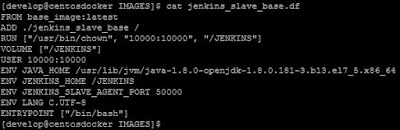 |
| Dockerfile de nuestra imagen base para un nodo slave de Jenkins. |
En este dockerfile hay unos cuantos puntos importantes a tener en cuenta:
- Las instrucciones COPY y ADD nos permiten añadir archivos a nuestra imagen como ya sabemos, pero lo importante es que siempre los añadirán como root, aunque el fichero o directorio origen sean de otro usuario.
- Debido al punto anterior, la segunda instrucción ejecuta el comando /usr/bin/chown dentro del contenedor temporal generado para crear la imagen. De este modo podemos cambiar la propiedad del directorio /JENKINS de la imagen. Esta instrucción RUN se ha ejecutado como root.
- Especificamos que el directorio /JENKINS de la imagen es un punto de
montaje de volúmenes. De este modo podremos mantener cualquier resultado
generado en una build en caso de ser necesario.
- Hasta este punto, todo se ha ejecutado como el usuario root en cualquiera de los contenedores temporales que se han ido generando para crear nuestra imagen. La siguiente instrucción define que el usuario a utilizar tiene el UID 10000, que es el usuario jenkins dentro de nuestra imagen, hará que cualquier otra instrucción RUN, CMD o ENTRYPOINT siguiente se ejecuten con dicho usuario. Por este motivo, la instrucción RUN que ha cambiado el propietario del directorio /JENKINS debe ir antes que la instrucción USER.
- A continuación definimos variables de entorno que serán necesarias en los contenedores generados para las diferentes builds.
Con este dockerfile contruimos la imagen y comprobamos que, efectivamente, los nuevos programas añadidos están disponibles en la nueva imagen y que funcionan correctamente.
Con nuestra imagen ya creada y tras comprobar que el software que hemos incluido en la misma funciona adecuadamente, modificamos el dockerfile de la imagen del siguiente modo:
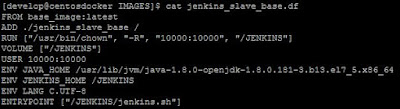 |
| Dockerfile de nuestra imagen base para jenkins. |
En este dockerfile solo hay una diferencia respecto al anterior, la definición de ENTRYPOINT es distinta y apunta a un script. Este script es muy simple, solo registra una entrada en el log del contenedor y luego lanza un comando sleep. La razón para esto es que, cuando Jenkins lanza un job en el que usa contenedores remotos como build agents, necesita un tiempo para poder engancharse con el contenedor y por tanto, si este se parase muy rápido, el build fallaría.
Ahora que tenemos nuestra imagen básica creada, la cual solo contiene de momento git y java, vamos a añadir la plantilla en la configuración de nuestro servidor Jenkins y crear nuestro job.
La configuración de la plantilla la realizaremos como podemos ver en la siguiente imagen:
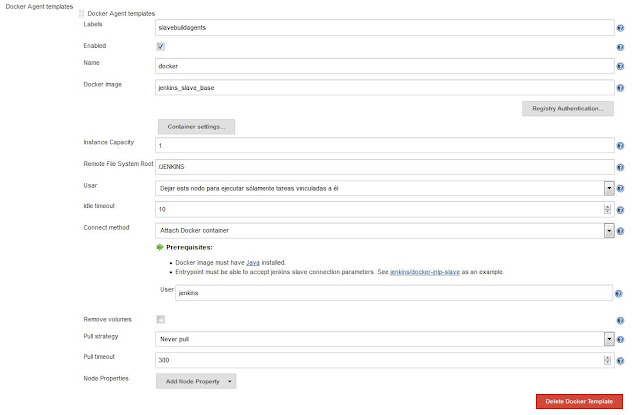 |
| Configuración de nuestra plantilla base en Jenkins. |
En la configuración anterior, uno de los puntos más importantes, es la etiqueta que le asignemos a esta plantilla ya que será la que luego usaremos en la definición de nuestro job. También debemos asegurarnos de especificar el nombre correcto de nuestra imagen Docker a utilizar, en este caso jenkins_slave_base.
Adicionalmente, si no especificamos en el campo Pull strategy la opción Never pull, Jenkins siempre intentará obtener la imagen para construir el contenedor de un repositorio remoto, en vez del repositorio local de nuestro dockerhost.
Con esta configuración de plantilla, nuestro job podemos configurarlo del siguiente modo:
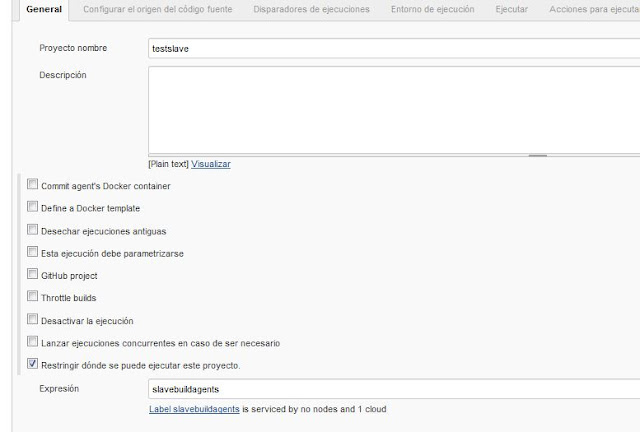 |
| Creación del job en Jenkins - Especificamos el uso de un contenedor docker específico. |
En el punto anterior vemos que, al especificar la misma etiqueta que hemos definido en el momento de crear la plantilla de docker, Jenkins indica que esta proporcionado por un proveedor de nube.
Realizamos cualquier configuración adicional que necesitemos para nuestro job, como obtener nuestra fuente de un repositorio git y lo lanzamos para comprobar que funciona correctamente:
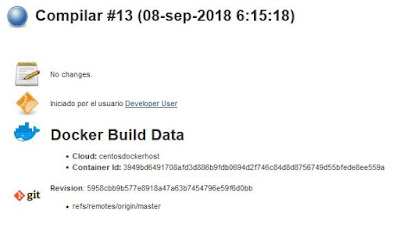 |
| Resultado del build usando un contenedor. |
Además del resultado anterior indicado por Jenkins, podemos comprobar en la salida por consola del job como se han realizado todos los pasos adecuadamente.
Adicionalmente, mientras se está ejecutando el job, si comprobamos en nuestro dockerhost la lista de contenedores corriendo vemos que aparece un contenedor adicional que, al finalizar el job desaparece ya que se crea como un contenedor efímero:
 |
| Contenedor lanzado como build agent por Jenkins. |
Ahora, si añadimos un compilador como por ejemplo gcc y creamos una nueva imagen a partir de esta, podremos configurar una nueva template en Jenkins que usaremos para compilar nuestro código C creando los jobs correspondientes.
Para crear una nueva template, tendremos que repetir la configuración de template anterior pero cambiando el nombre de la etiqueta, así como el nombre de la imagen a utilizar para construir los contenedores. Por ejemplo, para el caso de un slave agent para realizar builds de código C, podríamos hacer algo como lo siguiente:
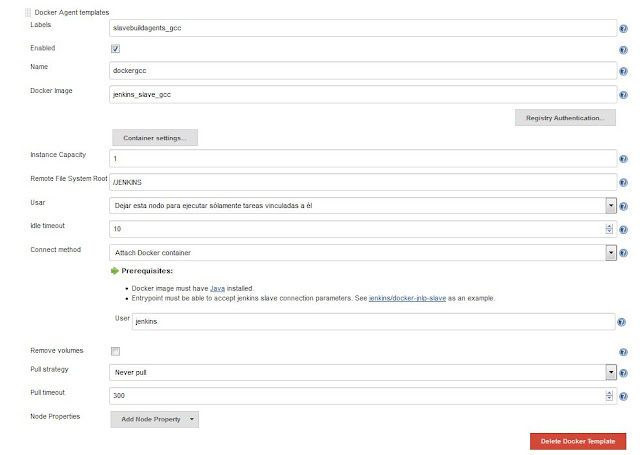 |
| Definimos una nueva template para usar la imagen que contiene el gcc. |
Ahora definimos un nuevo job que haga uso de esta template y que realice la compilación del código fuente que obtiene de nuestro repositorio git, con lo que el job quedaría más o menos con esta configuración:
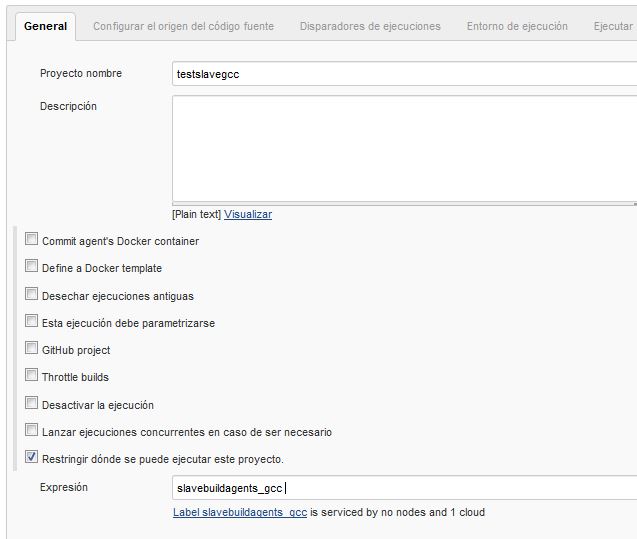 |
| Configuración del job - Definición de la template Docker a utilizar. |
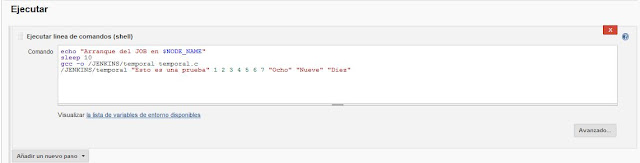 |
| Configuración del job - Definición de tareas simples de ejecución. |
Con esta configuración de job, la salida por consola del job que obtenemos es la siguiente:
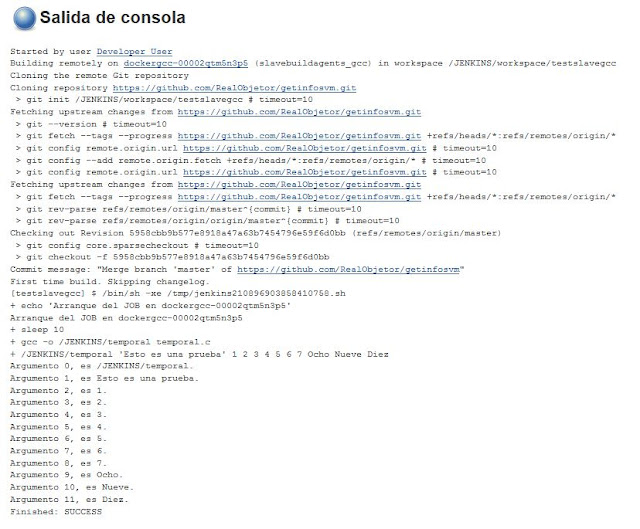 |
| Resultado de la ejecución de nuestro job. |
Por tanto, como podemos ver, es posible integrar Jenkin con nuestra infraestructura Docker para poder usar de una manera mucho más óptima nuestros recuursos. De este modo Jenkins es capaz de lanzar contenedores efímeros como agentes para nuestros entornos CI/CD permitiedo mucha más flexibilidad y aprovechamiento de los recursos.