Vamos con otra entrada rápida sobre OpenLDAP y más
concretamente, cómo podemos integrar Kerberos para usar un servidor
OpenLDAP como backend.
Y ¿en que consiste exactamente esto? Como ya
sabemos, Kerberos es un protocolo de autenticación de red basado en
el intercambio de tickets para la validación de usuarios y
servicios. Como cualquier servicio de autenticación, Kerberos
necesita una base de datos para almacenar su información así que,
lo que veremos en este artículo es como podemos configurarlo para
que esa base de datos sea un servidor OpenLDAP. Para más información
sobre Kerberos os recomiendo consultar la web
del MIT donde podréis encontrar información detallada al respecto.
Como es lógico, partimos de un servidor donde
tendremos instalado OpenLDAP y donde instalaremos los paquetes
necesarios para poder crear nuestro servidor Kerberos, incluyendo el
que permite usar un LDAP como backend. En el caso de un sistema
CentOS 7.8, estos paquetes son:
 |
| Paquetes necesarios para un servidor Kerberos5. |
A continuación necesitamos extender el schema del
servidor OpenLDAP para añadir los atributos y clases de objeto
necesarios para Kerberos. Esta extensión de schema, para la carga
dinámica en OpenLDAP, es un fichero proporcionado con el código
fuente de Kerberos distribuido por el MIT. Por tanto necesitamos
descargarnos las fuentes de Kerberos de al menos la versión 1.18.1,
la cual incluye un fichero de schema específico para OpenLDAP. Sin
embargo, si utilizas un servidor LDAP diferente como 389 Directory
Server, el paquete krb5-server-ldap incluye los ficheros de schema compatibles con dicho servidor de directorio:
 |
| Ficheros de schema incluidos en el paquete krb5-server-ldap. |
Para extender el schema solo tenemos que realizar
una operación add con un usuario con permisos en la rama config de
OpenLDAP. Para esto usaríamos un comando como el siguiente:
 |
| Extensión del schema de OpenLDAP. |
Los siguientes pasos consisten en realizar toda la
configuración necesaria para establecer un reino Kerberos,
especificando que vamos a utilizar como backend un servicio LDAP.
De forma muy resumida, un servidor Kerberos se basa
en dos servicios diferentes, el Key Distribution Center (KDC),
encargado de validar a los usuarios y hosts y proporcionarles los
tickets o claves correspondientes para acceder a los diferentes
servicios y el servidor de administración de Kerberos (kadmind),
encargado de realizar operaciones de administración sobre la base de
datos de Kerberos.
La integración de Kerberos con un backend LDAP
implica la creación de un objeto contenedor en el árbol del
servidor de directorio, el cual contendrá toda la información del
reino Kerberos. Para controlar el acceso a dicho contenedor, es
necesario definir un DN específico que será el único con permisos
sobre el mismo y crear dicho DN en nuestro árbol de directorio. Este
DN debemos especificarlo en el fichero de configuración del KDC y
crearlo manualmente antes de continuar, con lo que tendríamos algo
parecido a lo siguiente:
 |
| Creación del DN necesario para la administración del contenedor Kerberos. |
Esta cuenta o DN, puede ser de cualquier clase de objeto
que contenga un campo password. Es importante que guardemos bien esta
contraseña porque la necesitaremos en un paso posterior.
Una vez creada esta entrada en el servidor LDAP,
podemos crear los ficheros de configuración necesarios para
Kerberos. En concreto es necesario que modifiquemos los ficheros:
- /etc/krb5.conf, que contiene la confiiguración del cliente Kerberos 5 del servidor.
- /var/kerberos/krb5kdc/kdc.conf, que contiene la configurción
del servicio KDC del servidor.
 |
| Fichero /etc/krb5.conf. |
Uno de los cambios importantes a realizar en este
fichero son las líneas dns_lookup_realm y dns_lookup_kdc que, en un
entorno productivo donde tengamos un servicio DNS, deberían ser
iguales a true, lo cual implicaría la creación de determinados RRs
en el servicio DNS.
Respecto al fichero de configuración
/var/kerberos/krb5kdc/kdc.conf, el contenido básico, puede ser algo
parecido a lo siguiente:
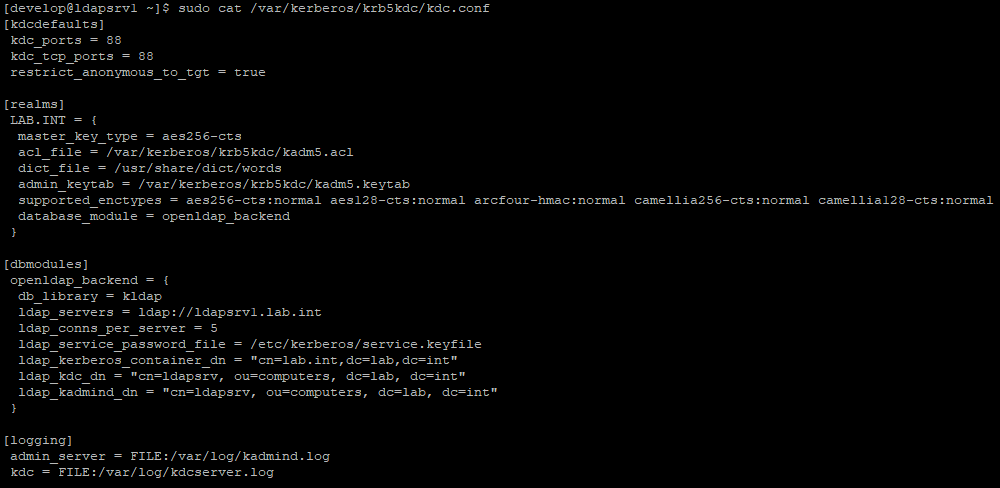 |
| Fichero /var/kerberos/krb5kdc/kdc.conf. |
En este fichero podemos ver la especificación del
DN que hemos creado anteriormente, así como la especificación del
servidor o servidores que emplearemos como backend para nuestro
servidor Kerberos. También es importante destacar la línea de
configuración ldap_kerberos_container_dn que especifica el DN que se
creará para almacenar la información del reino Kerberos. El nombre
de dicho DN esté especificado con un atributo commonName (cn) debido
a que la clase de objeto que se creará en el momento de creación
del reino Kerberos, requiere un atributo commonName.
Otro punto importante, para evitar problemas, si
especificamos en dicho fichero alguna ruta que no existe, es
importante crearla manualente antes de continuar.
Con esta configuración ya establecida, el siguiente
paso consistirá en crear el fichero con la password de servicio, definido por la opción ldap_service_password_file.
Este fichero contendrá la password que emplearán los servicios KDC
y kadmin, para conectarse al servidior LDAP. Por tanto, esta password
debe coincidir con la que hemos especificado antes al crear el DN
que accederá al contenedor del reino Kerberos en LDAP. El
comando que empleamos es el siguiente:
| Creación del fichero con la password de servicio. |
Ahora crearemos el reino Kerberos, así como el
fichero stash con la password maestra de la base de datos con lo que
es importante tener en cuenta los siguientes puntos:
- Al usar LDAP como backend, el comando a utilizar para la creación del reino es kdb5_ldap_util.
- Debemos decidir si queremos que los principales se creen en un subtree diferente al del contenedor del reino Kerberos. Este punto podemos establecerlo con la opción -subtrees, donde especificaremos el DN donde queremos almacenar los principales del reino Kerberos.
- Debemos especificar el servidor LDAP así como un DN con permisos de escritura en el árbol de directorio.
- Al crear el fichero stash especificaremos una password que no tiene porque ser igual que la password de servicio LDAP especificada anteriormeente.
 |
| Creación del reino Kerberos. |
Con este comando creamos el contenedor Kerberos en el árbol del servidor OpenLDAP y, al no usar la opción -subtrees, los principales se crearán en el contenedor correspondiente al reino Kerberos.
Si comprobamos el árbol de directorio, podremos ver
que ahora aparece una nueva entrada que contiene la información
básica de nuestro reino Kerberos:
 |
| Contenedor Kerberos creado en el árbol del servidor LDAP. |
Para asegurar que solamente los DNs establecidos en
la configuración del KDC, especificados con las opciones ldap_kdc_dn
y ldap_kadmind_dn, pueden acceder al contenedor del reino Kerberos y
evitar accesos no permitidos, creamos unas ACLs básicas. Estas ACLs
podemos crearlas usando un editor LDAP en la rama cn=config,
correspondiente a la base de datos que contenga el contenedor de
Kerberos, del servidor OpenLDAP. Unas ACLs básicas serían las
siguientes:
 |
| ACLs básicas para el control de acceso. |
Además es recomendable añadir un índice de tipo igualdad (eq) para el atributo krbPrincipalName, lo cual acelarará las búsquedas en el servidor. Para añadir el atributo solo tenemos que modficar la configuración de la base de datos correspondiente del siguiente modo:
 |
| Añadiendo un índice eq para el atributo krbPrincipalName. |
Con esta configuración establecida, podemos arrancar los servicios krb5kdc y kadmind:
 |
| Arranque de los servicios KDC y kadmind. |
Una vez arrancados los servicios, podemos comprobar que todo funciona correctamente creando un principal y comprobando que este aparece en el contenedor del reino Kerberos. Podemos crear un principal de forma simple usando el comando kadmin.local:
 |
| Creación de nuevos principales. |
Y como podemos comprobar, este nuevo principal aparece en el contenedor del reino Kerberos:
 |
| Nuevo principal en contenedor Kerberos del reino LAB.INT. |
De este modo comprobamos que la integración entre el servicio Kerberos y el servidor OpenLDAP es correcta. Si borramos el principal reciend creado con el comando kadmin.local, el cual solo debe lanzarse desde el servidor que contenga el kdc, tendríamos lo siguiente:
 |
| Borrado de un principal. |
 |
| Principal eliminado en OpenLDAP. |
Por tanto, hemos integrado Kerberos con OpenLDAP para usar este último como backend o base de datos de un servicio Kerberos. La principal ventaja que conseguimos al hacer esto es que ahora podemos instalar más servidores OpenLDAP y Kerberos y, utilizando las características de replicación proporcionadas por OpenLDAP, tener un servicio de nombres y autenticación distribuido y tolerante a fallos.
Por último, si queremos asegurarnos que el servicio Kerberos arranca correctamente, es necesario que incluyamos una dependencia en los servicios krb5kdc y kadmin con el servicio slapd del siguiente modo:
 |
| Incluyendo dependencia con slapd. |
En próximas entradas veremos como configurar esta replicación entre varios servidores OpenLDAP y como podemos configurar SASL en OpenLDAP para emplear el mecanismo de autenticación GSSAPI para la validación de usuarios y servicios.