Hace demasiado que no publicaba una nueva entrada sobre la pila ELK, la última entrada tiene más de un año, así que hoy vamos con un nuevo post en el que vamos a utilizar las capacidades de ingesta de Elasticsearch y, con los datos que tengamos, realizaremos una gráfica simple.
En las entradas anteriores enviabamos datos a Logstash, para procesarlos y crear documentos con los campos necesarios para posteriormente almacenarlos en un índice de Elasticsearch. Además, también vimos como crear un índice y definíamos el tipo de dato específico de los campos que nos interesan.
Desde entonces ha llovido mucho y aunque continuamos con una configuración similar, vamos a introducir un pequeño cambio y usaremos un nodo de elasticsearch como nodo de ingesta, en el cual podremos definir un pipeline para procesar los datos que recibimos sin necesidad de usar Logstash. Básicamente, lo que estamos haciendo es pasar la funcionalidad de Logstash directamente al cluster de Elastic.
Para esto, vamos a empezar de forma sencilla analizando los mensajes que vamos a recibir desde un nodo que nos envía información mediante filebeat, la cual vamos a generar usando syslog_generator:
 |
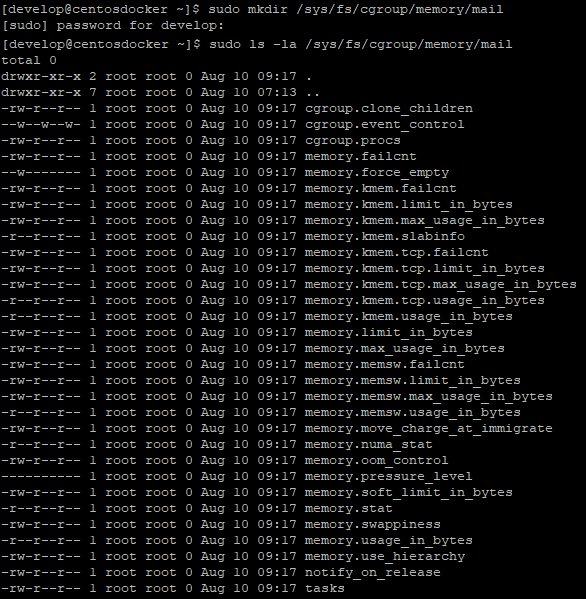
Mensajes recibidos desde filebeat.
|
Como vemos, filebeat envía una gran cantidad de campos que no nos interesan, ya que solo queremos quedarnos con el campo message que contiene el mensaje real creado por syslog_generator.
Vamos a empezar de forma simple creando un pipeline en Elastic que elimine todos esos campos que nos sobran. Para este tipo de tareas, como siempre, lo mejor es utilizar la consola de desarrollo de Kibana. Veamos directamente el pipeline para analizarlo posteriormente:
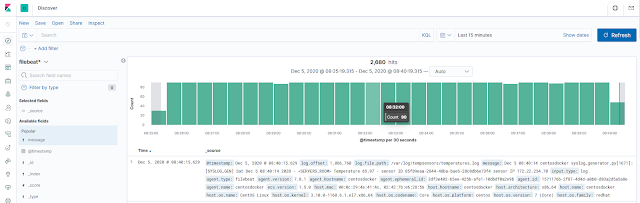
 |
Pipeline básico de eliminación de campos.
|
Con este pipeline definimos que queremos eliminar una serie de campos de los mensajes recibidos, en concreto los que aparecen en el campo field dentro del procesador remove, que podemos ver en la imagen superior.
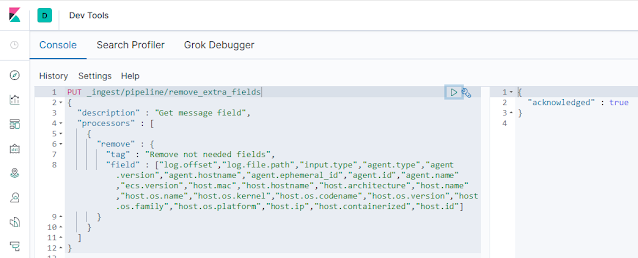
Una vez definido un pipeline, este queda almacenado en el cluster, pero para usarlo necesitamos asociarlo a un índice. Para seguir con nuestras pruebas, lo que hacemos es editar el índice que se ha creado automáticamente en el cluster en cuanto ha empezado a recibir datos de los nodos con filebeat y modificamos su atributo index.default_pipeline. Este atributo establece que pipeline hay que aplicar a los documentos recibidos antes de almacenarlos en el índice. Podemos editarlo desde la opción Edit Settings de la sección Index Management:
 |
Modificación de las propiedades del índice.
|
Al especificar que debe aplicarse el pipeline a los documentos antes de almacenarlos, todos los campos que hemos indicado dentro del procesador remove del pipeline son eliminados, con lo que ahora podemos ver lo siguiente desde la sección Discover para el patrón del índice generado por filebeat:
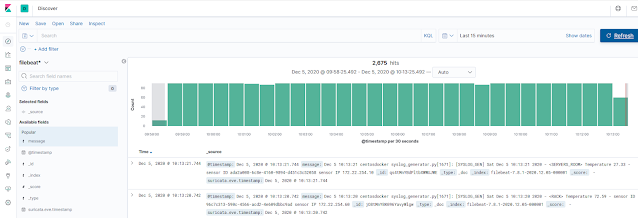 |
Documentos en el índice filebeat tras pasar por el pipeline.
|
Como vemos, ahora cada documento se ha almacenado en el índice sin los campos que hemos eliminado anteriormente.
Para llegar a este punto hemos tenido que modificar manualmente el índice que se ha creado de forma automática pero, como esto no es muy operativo que se diga, empecemos por establecer en la configuración de filebeat que pipeline debe utilizarse estableciendo la opción pipeline en el fichero filebeat.yml de nuestro nodo filebeat origen:
 |
Configuracion de filebeat aplicando el pipeline.
|
Por tanto, como vemos, podemos aplicar el pipeline a la salida configurada de filebeat en origen directamente. Al hacerlo comprobamos que todos los campos que hemos configurado en el procesador remove del pipeline remove_extra_fields, no se han almacenado en los documentos del índice filebeat.
Por tanto, ahora que tenemos claro que podemos pasar cierta funcionalidad de Logstash directamente a Elasticsearch, pasemos a hacer un pipeline que procese nuestro campo message adecuadamente, nos devuelva los campos que necesitamos, elimine el resto y para finalizar, escriba los documentos en un índice diferente, donde estableceremos los mapeos necesarios para cada campo, asegurándonos que el tipo de dato de cada uno se almacena de forma correcta.
El pìpeline que realiza toda la manipulación de campos que necesitamos es el siguiente:
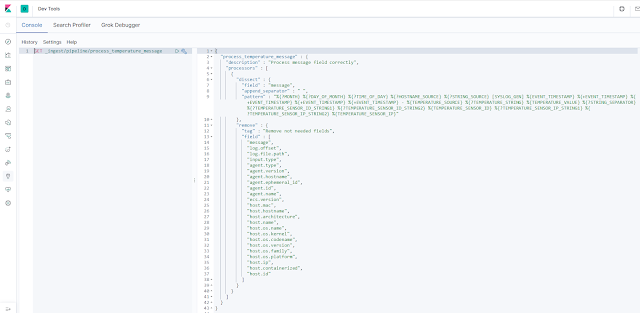 |
Pipeline de eliminación de campos y procesado del campo message.
|
Como en la imagen anterior no queda muy claro, podéis encontrar el pipeline completo, junto con la creación del índice definitivo, anexado con este post.
Ya hemos comprobado que este pipeline modifica el documento, eliminando aquellos campos que no necesitamos y crea los nuevos campos a partir del procesado del campo message original. A continuación crearemos un índice especificando los campos que necesitamos en cada documento y, lo más importante, con el tipo de dato correcto. Ya sabemos que, para crear un índice, lo mejor es usar la consola de desarrollo de Kibana. Podemos crear el índice de una manera similar a la siguiente:
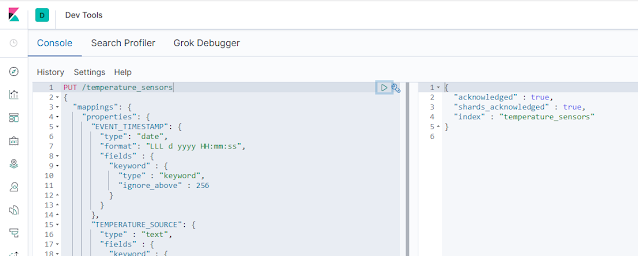 |
Creación del índice.
|
Una vez creado nuestro nuevo índice, creamos el index pattern necesario para que Kibana pueda obtener datos de Elasticsearch. Para esto, desde el menú Management, en la sección Index Patterns de Kibana, creamos el nuevo patrón especificando que el campo @timestamp es el que contiene la información de fecha y hora para poder hacer el filtrado por tiempo:
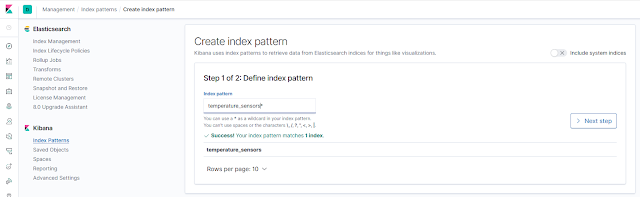 |
Creación del index pattern correspondiente al nuevo índice.
|
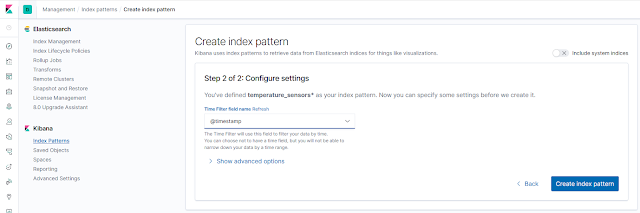 |
Seleccion del campo de fecha del index pattern.
|
Es importante que nos demos cuenta que el campo @timestamp de cada documento contiene la fecha y hora de recepción de la información enviada por filebeat, la cual no es la misma que aparece en el campo message. Para corregir esto, el pipeline hace una conversión del campo EVENT_TIMESTAMP que hemos construido con el procesador dissect y copia dicha información en el campo @timestamp. Esta operación de conversión la realiza el siguiente procesador:
 |
Modificación del campo @timestamp.
|
A continuación cambiamos la configuración de filebeat en el nodo origen para especificar el nombre del pipeline que deseamos usar antes de almacenar los documentos en el índice:
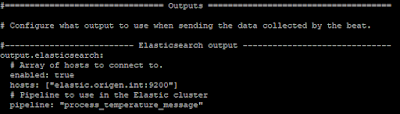 |
Configuración definitiva de filebeat.
|
Con toda la configuración ya realizada, podemos comprobar como tenemos datos en el índice en los campos deseados y con el tipo de dato correcto:
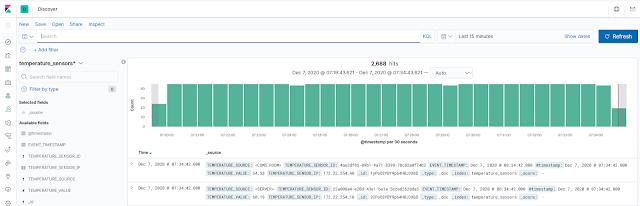 |
Datos del indice temperature_sensors.
|
Ya con nuestros datos, podemos pasar a hacer una representación gráfica simple de los valores de temperatura recibidos desde la sección Visualize. Podemos crear una gráfica de tipo lineal para ver los valores medios de temperatura:
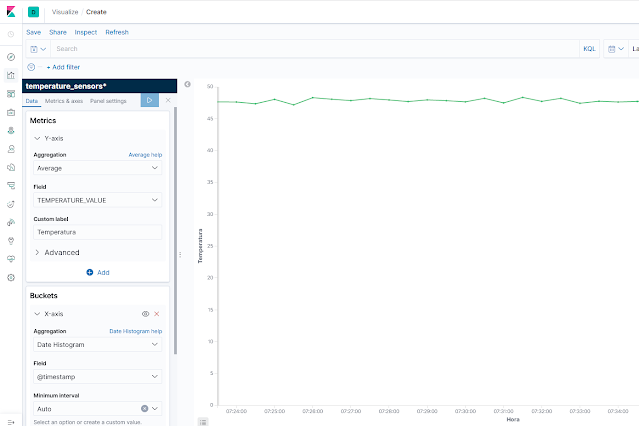 |
Valores medios de temperatura.
|
Esta representación nos muestra los valores medios de temperatura para cada intervalo temporal que seleccionemos. Para esto establecemos que en el eje Y queremos el valor medio del campo TEMPERATURE_VALUE de cada documento y, en el eje X establecemos un histograma basado en el campo de fecha y hora @timestamp.
El problema de esta visualización, es que estamos obteniendo el valor medio de los valores de temperatura enviados por tres sensores diferentes. Para mostrar en la misma gráfica el valor medio de temperatura, por cada uno de los sensores que estamos simulando con syslog_generator, tenemos que añadir filtros en el eje X para los identificadores de cada uno de los sensores. Esto podemos hacerlo más o menos del siguiente modo:
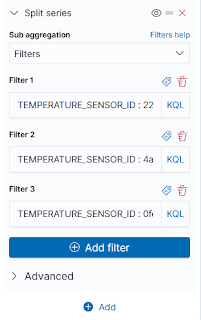 |
Filtro por cada sensor.
|
Al realizar esta configuración, pasamos a tener una gráfica como la siguiente:
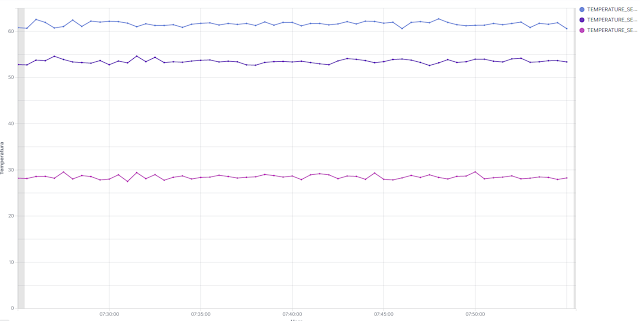 |
Valor medio de temperatura por cada sensor.
|
Es importante tener en cuenta que cada uno de los valores que vemos en cada gráfica, se corresponden con el valor medio de todos los valores recibidos en ese intervalo de tiempo. Si aumentamos la resolución, disminuyendo el tiempo de representación de la gráfica, podemos ver algo como lo siguiente:
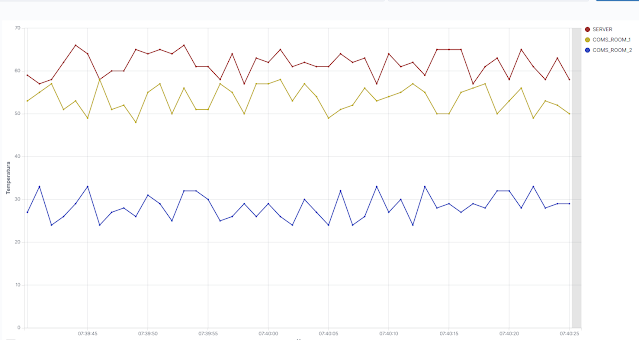 |
Valores de temperatura por segundo de cada sensor.
|
En esta gráfica ya tenemos una resolución de un segundo, correspondiente a la tasa de envío de información que he configurado en syslog_generator para simular la información de temperatura de cada sensor simulado.
Por tanto y en resumen, hemos visto como crear un pipeline que nos permite procesar los documentos que llegan a Elasticsearch, sin necesidad de utilizar Logstash, hacer las modificaciones necesarias para obtener los campos que nos interesan y almacenar dichos documentos en un índice diferente.
Además, basándonos en dichos datos, hemos creado una gráfica simple en la que hemos podido aplicar filtros para diferenciar entre diferentes fuentes del mismo índice.
En el siguiente enlace podéis encontrar el fichero que contiene la definición del pipeline así como la del índice utilizados a lo largo del post.