Hace ya unos cuantos meses vimos como podíamos integrar Kerberos con un servidor OpenLDAP, creando así un servicio de nombres y autenticación en el cual OpenLDAP se utiliza como base de datos para los principales de Kerberos, así como para almacenar información de cuentas de usuarios y grupos para sistemas Unix/Linux. Aprovechando las funcionalidades de replicación de OpenLDAP, conseguíamos posteriormente un despliegue con tolerancia a fallos.
Para continuar mejorando lo que hicimos entonces, vamos a establecer las medidas de seguridad necesarias que aseguren que las comunicaciones entre los diferentes elementos que forman la solución se encriptan siempre que sea posible.
Empezando por lo más sencillo, es necesario establecer unas reglas en los cortafuegos que solo permitan las conexiones a los puertos requeridos de cada uno de los servicios proporcionados. En concreto es necesario crear reglas para permitir las conexiones a los siguientes puertos:
- Puertos 389 y 636. Puertos de servicio de OpenLDAP para establecer conexiones cifradas mediante StartTLS y ldaps respectivamente.
- Puerto 88. Puerto de servicio del KDC de Kerberos. Necesario para realizar la autenticación de usuarios mediante la petición y expedición de tickets.
- Puertos 464 y 749. Puertos del servicio kadmin de Kerberos para el proceso de cambio de contraseñas.
Una vez establecidas estas reglas básicas de cortafuegos, el siguiente paso es cifrar las comunicaciones entre los servidores OpenLDAP y los clientes que deban acceder a los mismos. Llegados este punto puede resultar interesante que consideremos el siguiente diagrama:
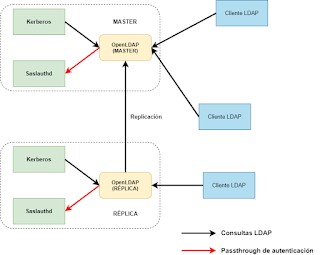 |
Relaciones entre los componentes de la solución.
|
Analizando el diagrama anterior y teniendo en cuenta que los servidores OpenLDAP son el repositorio central de toda la arquitectura del servicio de nombres y validación que queremos desplegar, está claro que es necesario cifrar todas las comunicaciones que se realicen desde cualquier cliente. Es importante señalar que, desde el punto de vista de OpenLDAP, Kerberos es un cliente de LDAP más, ya que este realizará consultas para buscar los principales correspondientes a todas aquellas peticiones de validación que reciba. También es importante señalar que para realizar el passthrough de autenticación, OpenLDAP delega el proceso de autenticar un usuario contra el KDC a través del servicio saslauthd que se encuentra corriendo en el mismo servidor.
Aunque posteriormente volveremos sobre este diagrama, empecemos por cifrar las comunicaciones entre OpenLDAP y los clientes existentes, incluido el servidor OpenLDAP secundario o réplica ya que, para utilizar el mecanismo de replicación syncrepl, se realizan consultas LDAP estándar así que, estas comunicaciones también podemos entenderlas como procedentes de un cliente LDAP.
Para cifrar las comunicaciones lo que necesitamos es disponer de un par clave privada-certificado por cada servidor. Podemos crear nuestra propia CA de forma simple con OpenSSL, crear certificados autofirmados o, si disponemos de una CA corporativa, generar dichos certificados en ella. En resumen, al final terminaremos con un par de ficheros en formato PEM que tendremos que copiar a nuestros servidores y configurar OpenLDAP para que los utilice para el cifrado de las comunicaciones.
Una vez copiados los ficheros y aprovechando el backend config, configuramos de forma dinámica los servidores, cambiando los siguientes atributos de configuración:
- olcTLSCACertificateFile, este atributo establece la ruta y fichero que contiene los certificados de todas las CAs en las que se confía.
- olcTLSCACertificatePath, este atributo establece la ruta que contiene los ficheros con los certificados de todas las CAs en las que se confía. Este parámetro es complementario al anterior y probablemente no sea necesario usar ambos.
- olcTLSCertificateFile, este atributo establece la ruta y fichero que contiene el certificado del servidor OpenLDAP.
- olcTLSCertificateKeyFile, este atributo establece la ruta y fichero que contiene la clave privada correspondiente al certificado del servidor OpenLDAP.
- olcTLSCipherSuite, este atributo establece que cifrados acepta el servidor OpenLDAP, así como el orden de los mismos. Es muy importante tener en cuenta que, el valor de este atributo, depende de la biblioteca SSL que se haya utilizado para la compilación de OpenLDAP. Esto quiere decir que, la cadena que utilicemos como valor para este atributo, debe ser entendida por la biblioteca. Como apunte para tenerlo en cuenta, en el caso de CentOS, OpenLDAP está compilado contra OpenSSL, mientras que en Debian está compilado contra GnuTLS.
Debido al impacto que tiene en las comunicaciones, de momento dejaremos de lado el atributo olcTLSCipherSuite así que, usando nuestro editor favorito de servidores LDAP, cambiamos adecuadamente el valor del resto de atributos de configuración en la rama cn=config y tendremos algo similar a lo siguiente:
 |
Configuración de certificados en OpenLDAP.
|
Es necesario asgurar que la ruta y permisos de estos ficheros son correctos o recibiremos un error al modificarlos, ya que el proceso slapd intentará acceder a los mismos y al no poder hacerlo, rechazará la modificación de dichos atributos.
A continuación, una vez configurados los certificados de ambos servidores, tenemos dos opciones para realizar el encriptado de las comunicaciones, levantar slapd con el puerto adicional 636 para el uso de ldaps o habilitar el uso de StartTLS sobre el puerto estándar 389. Veamos un poco las diferencias entre ambas soluciones:
- ldaps, también conocido como LDAP seguro, es el mecanismo diseñado originalmente para LDAPv2 que permite confidencialidad en las comunicaciones entre un servidor OpenLDAP y un cliente. Se inicia en el momento de establecer la conexión entre el servidor y el cliente y requiere el uso de un puerto adicional que, por defecto, es el 636.
- StartTLS es el mecanismo estándar defiinido en la RFC 2830 para LDAPv3. En esta RFC se establece el procedimiento para que, una vez que se ha establecido correctamente la conexión LDAP entre cliente y servidor, se habilite el uso de TLS/SSL para cifrar la comunicación sobre el puerto 389 estándar de cualquier servidor LDAP.
Lo cierto es que, una vez establecida la conexión cifrada, no hay diferencia entre ambas soluciones, salvo por el uso de un puerto adicional en el caso de ldaps. Como el uso de una u otra solución dependerá de las necesidades de los clientes que vayan a conectarse, es importante considerar ambas para fijar una u otra, pero es importante tener en cuenta que es preferible usar StartTLS siempre que sea posible.
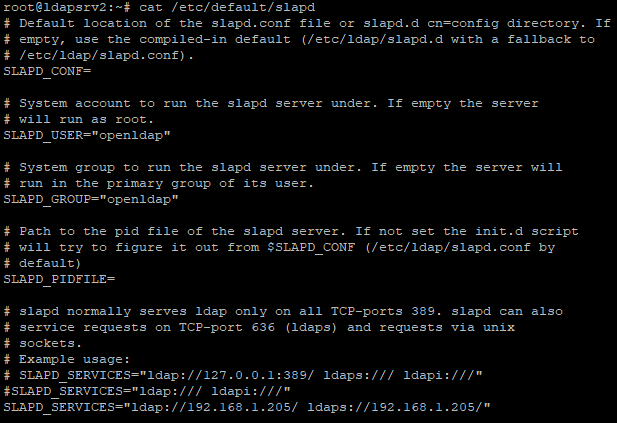
Teniendo en cuenta las diferencias entre ldaps y StartTLS, de momento vamos a configurar ambas empezando por la sencilla. Para configurar ldaps, solo tenemos que levantar el servidor OpenLDAP especificando una URL adicional para ldaps. En general, haremos esto modificando el fichero slapd que define los parámetros utilizado para arrancar el servicio. En función de la distribución utilizada, este fichero se encontrará en una ruta u otra. En el caso de usar CentOS o Debian, estos ficheros están en /etc/sysconfig y /etc/default respectivamente:
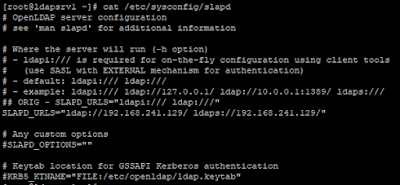 |
Configuración URL ldaps - CentOS.
|
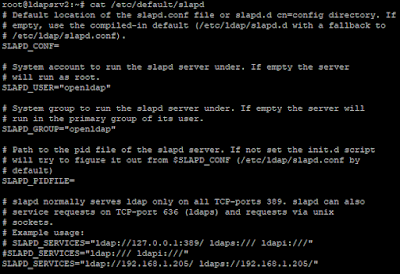 |
Configuración URL ldaps - Debian.
|
Tras realizar este cambio y reiniciar el servicio slapd, este escuchará en el puerto 636 presentando el certificado obtenido inicialmente para cada servidor. Al conectar de nuevo al servidor desde un cliente LDAP, debemos escoger como puerto de conexión el 636 y SSL como método de encriptación, con lo que estaremos usando ldaps para conectarnos con el servidor. Usando Apache Directory Studio recibiremos un mensaje, acerca del certificado presentado por el servidor OpenLDAP, como el siguiente al establecer la conexión por primera vez al puerto 636:
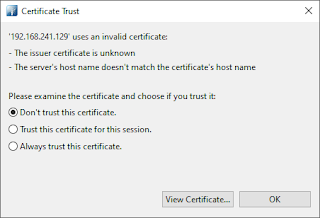 |
Verificación de certificado de servidor.
|
De este modo tan simple, podemos asegurar que la conexión entre nuestro cliente y el servidor OpenLDAP está cifrada protegiendo de momento mediante ldaps, las tareas de administración que realicemos.
A continuación vamos a cifrar el tráfico de replicación entre el servidor master y el servidor réplica de la infraestructura, para lo cual usaremos StartTLS en vez de ldaps. Para esto, una de las primeras comprobaciones que debemos hacer ,es verificar que el servidor soporta la extensión StartTLS definida en la RFC 2830. Podemos comprobarlo mediante una búsqueda sencilla con ldapsearch o bien usando un editor LDAP. En general, mediante un comando ldapsearch, el resultado que debemos obtener es similar al siguiente:
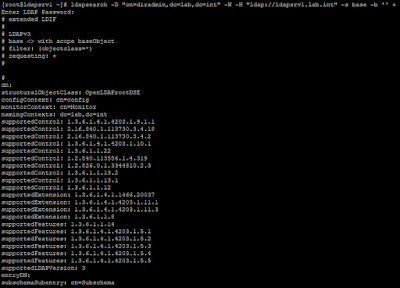 |
Lista de controles, características y extensiones soportadas.
|
Entre todos los OIDs que se muestran en la salida anterior, el correspondiente a StartTLS es el 1.3.6.1.4.1.1466.20037 como se describe en la RFC 2830. Esto indica que cuando configuremos cualquier cliente para emplear StartTLS, este enviará este OID en una petición extendida solicitando el uso de dicha extensión. Al estar soportada por el servidor, la conexión LDAP establecida pasará a estar cifrada entre ambos servidores para el tráfico de replicación.
Para configurar el uso de StartTLS entre ambos servidores, solo es necesario modificar el atributo olcSyncRepl existente en el servidor réplica, ya que hay que recordar que en OpenLDAP, la operación de replicación se inicia desde los servidores réplica y que en el servidor maestro solo es necesario habilitar el overlay syncprov para permitir las replicaciones.
En este caso, lo más recomendable es utilizar un editor gráfico LDAP para realizar la modificación de este atributo, el cual está definido en la rama cn=config de configuración dinámica del servidor. Para forzar el uso de StartTLS entre los servidores, las opciones que debemos añadir al atributo olcSyncRepl son las siguientes:
- starttls=yes o critical, para establecer la sesión TLS antes de realizar la operación de autenticación con el servidor LDAP maestro. Si usamos la opción critical, la replicación fallará en caso de no poder iniciarse la sesión TLS. Si especificamos yes, pasará a usar ldap no cifrado en caso de fallo en el establecimiento de la sesión TLS.
- tls_cert, tls_key, tls_cacaert y tls_cacertdir, para establecer la ruta a los ficheros de certificado, tanto de CAs como del propio servidor, así como al fichero que contiene la clave privada del servidor LDAP réplica.
- tls_reqcert=demand, para forzar al servidor maestro el presentar su certificado para la conmprobación del mismo.
Teniendo en cuenta todas estas opciones, lo único que necesitamos es cambiar el atributo del siguiente modo:
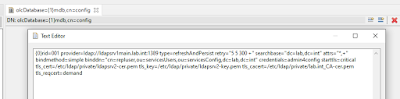 |
Modificación de olcSyncRepl en servidor réplica.
|
Aunque hemos usado el backend de configuración dinámica y estas opciones se empiezan a utilizar en el momento de establecerlas, es necesario reiniciar el servidor réplica. Una vez hecho esto, lo primero es comprobar que la replicación funciona correctamente, para lo cual basta con añadir una nueva entrada o modificar una ya existente y confirmar que los cambios se replican adecuadamente.
Podemos comprobar que, efectivamente, se está realizando la replicación MASTER-RÉPLICA de forma cifrada mediante el comando tcpdump:
 |
Replicación cifrada entre master y réplica.
|
Estos paquetes los veremos en el momento de realizar cualquier modificación en el servidor master y, como se puede apreciar, el tráfico de replicación está cifrado entre ambos servidores. Adicionalmente, podemos comprobarlo en los logs de ambos servidores:
 |
Sesión TLS entre servidor master y réplica.
|
Y por último, aseguramos que la replicación es correcta verificando que el contextCSN de ambos servidores es idéntico:
 |
ContextCSN del servidor MASTER.
|
 |
ContextCSN del servidor RÉPLICA.
|
Por tanto, llegados a este punto, tenemos cifradas las comunicaciones entre los clientes LDAP como pueden ser las herramientas administrativas así como la replicación entre el servidor MASTER y los servidores RÉPLICA existentes.
Ahora, recordando el análisis realizado al principio del post y para terminar, es necesario que establezcamos la seguridad de las comunicaciones necesarias entre los servicios de Kerberos y el servidor OpenLDAP. Como ya se estableció, desde el punto de vista de OpenLDAP, tanto el servicio kdc como el servicio kadmin, son clientes LDAP, los cuales debemos configurar adecuadamente para o bien utilizar ldaps o emplear StartTLS.
Como ya vimos en el
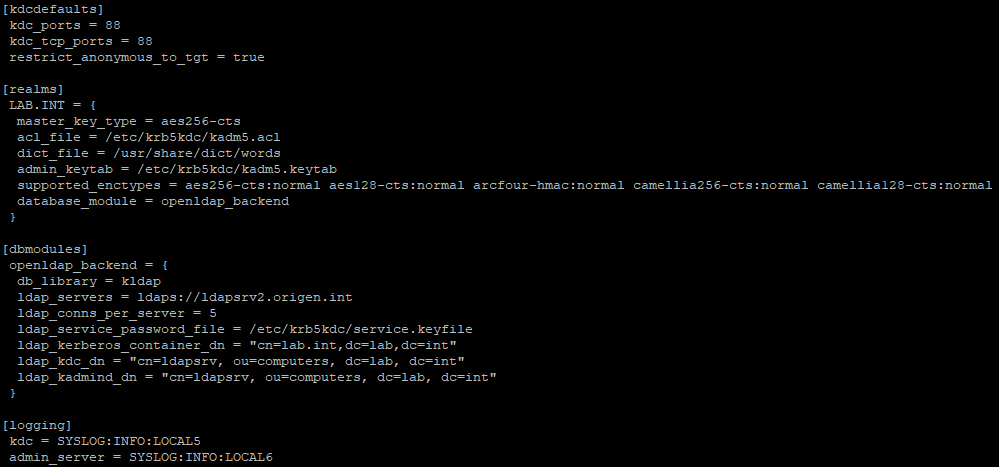
post en el que integrábamos Kerberos con un backend OpenLDAP, toda la configuración necesaria debemos realizarla en el fichero kdc.conf, el cual se encuentra en la ruta /var/kerberos/krb5kdc en sistemas CentOS o en la ruta /etc/krb5kdc en el caso de sistemas Debian. El fichero que generamos entonces es similar al siguiente:
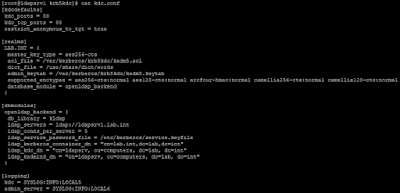 |
Fichero de configuración kdc.conf.
|
Revisando la documentación de Kerberos comprobamos que, a la hora de especificar la URL de los servidores LDAP, lo recomendado es emplear ldaps para asegurar que la comunicación entre los servicios de Kerberos y OpenLDAP está cifrada.
En este caso, como Kerberos hará uso de las bibliotecas LDAP del sistema operativo, lo primero que debemos hacer es configurar el fichero ldap.conf. En este fichero se establece la configuración del cliente ldap del sistema, indicando la ruta al fichero que contendrá el certificado de la CA que ha firmado el certificado empleado por OpenLDAP. Para realizar esta configuración solo necesitamos modificar la opción TLS_CACERT indicando la ruta al fichero, o la opción TLS_CACERTDIR, para indicar la ruta al directorio donde se encuentran los ficheros con los certificados de las CAs en las que se confía:
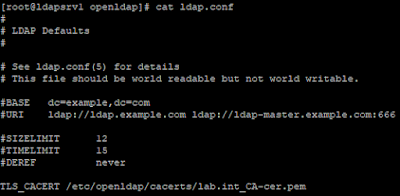 |
Fichero ldap.conf.
|
Con esta configuración establecida, solo necesitamos modificar el fichero kdc.conf e indicar como URL de acceso ldaps:// en el parámetro de configuración ldap_servers. El fichero quedaría más o menos así:
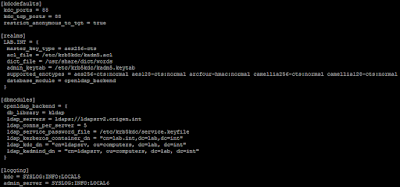 |
Fichero kdc.conf modificado para usar ldaps.
|
Una vez realizado este cambio solo nos falta reiniciar los servicios y comprobar que estos arrancan y se conectan al puerto 636 correctamente:
 |
Conexiones del servicio kdc mediante ldaps.
|
 |
Conexiones del servicio kadmin mediante ldaps.
|
Llegado este punto, las comunicaciones entre los diferentes elementos del sistema que establecen conexiones con el servidor OpenLDAP están cifradas pero, para terminar de asegurar que solo se permiten este tipo de conexiones, es necesario que configuremos el propio servidor OpenLDAP para que exija el uso de confidencialidad en todas las conexiones. Para esto, lo único necesario es que establezcamos el atributo de configuración olcSecurity con el valor ssf=1. Al establecer este atributo, cualquier conexión no cifrada se rechazará con el mensaje confidentiality required sin necesidad de reiniciar el servidor OpenLDAP:
 |
Mensaje de error para conexiones no cifradas.
|
En resumen, hemos establecido las configuraciones mínimas necesarias para establecer la encriptación y por tanto confidencialidad de las comunicaciones entre el servicio OpenLDAP y los clientes existentes, incluyendo los servicios de Kerberos que emplean el servidor LDAP como backend. Además hemos establecido que el servidor OpenLDAP exija siempre el uso de encriptación en cualquier conexión que se establezca, lo que provoca que no puedan realizarse conexiones no encriptadas al puerto 389. Teniendo esto último en cuenta, para comprobar el contextCSN de cada uno de los servidores, ahora necesitamos realizar el comando ldapsearch especificando la opción -Z del siguiente modo:
 |
Comprobación del contextCSN mediante StartTLS.
|
Tengamos en cuenta que, al haber configurado el cliente ldap del sistema, especificando la ruta al fichero que contiene el certificado de la CA en ldap.conf, las herramientas como ldapsearch usarán dicha configuración para establecer la comunicación mediante StartTLS correctamente.
Para terminar, solo falta impedir que se puedan realizar operaciones bind anónimas, para lo cual solo es necesario que cambiemos el atributo de configuración dinámica olcDisallows y especifiquemos bind_anon lo cual queda más o menos así:
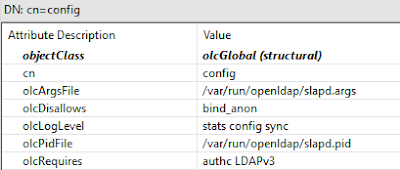 |
Deshabilitando el bind anónimo.
|
También es recomendable establecer que se requiere siempre autenticación, para realizar cualquier tipo de operación en el servidor de directorio, así como requerir siempre el uso del protocolo LDAPv3. Estas opciones podemos establecerlas modificando el atributo olcRequires como se ve en la imagen anterior. Con estos cambios, al intentar hacer una búsqueda empleando un bind anónimo, recibimos un mensaje como el siguiente:
 |
Error en operaciones con bind anónimos.
|
Este cambio provoca que cualquier cliente que hayamos configurado, que realice operaciones bind anónimas, requiera ahora de un usuario del directorio, especificado por su DN y una contraseña. Como veremos en futuras entradas, esta configuración es muy importante cuando configuramos cualquier sistema Unix/Linux para que utilice un servidor OpenLDAP como servicio de nombres y requerirá la correcta configuración del servicio nslcd o sssd.
En próximas entradas, veremos como integrar un servidor DNS con OpenLDAP así como emplear tickets Kerberos para el acceso a los diferentes servicios, especificando diferentes mecanismos SASL para la validación al realizar operaciones.