Hoy continuamos con la administración de Docker swarm y en concreto, vamos a repasar como usar volúmenes con los servicios que desplegamos en nuestros clusters de dockerhosts.
Originalmente, como ya vimos en su momento, se usaba la opción -v o --volume, para montar volúmenes con nuestros contenedores standalone y, para el despliegue de servicios, se usaba la opción -m o --mount. Desde la versión 17.06 de Docker lo recomendado es usar --mount en ambos casos, aunque se sigue soportando el uso de --volume con contenedores standalone.
Recordando un poco lo que ya sabemos de Docker, hay dos tipos de montajes o volúmenes que podemos usar. Los dos tipos de montajes o volúmenes disponibles son:
- Volúmenes de datos (volume mounts). Estos son los volúmenes independientes de nuestros dockerhosts y que deben ser gestionados de manera separada. Lo lógico es que estos volúmenes los proporcionen sistemas de almacenamiento específicos y que, mediante un driver determinado, podamos interactuar con el proveedor del almacenamiento y administrar los volúmenes.
- Volúmenes de tipo bind. De forma muy simple estos son volúmenes que están en cada dockerhost del swarm, es decir son rutas dentro del sistema de archivos de nuestros dockerhosts.
Como ya he comentado, aunque se sigue soportando la opción -v o --volume, lo recomendado es usar siempre la opción -m o --mount, independientemente del tipo de volumen a usar. Al montar nuestros volúmenes con --mount podremos especificar diferentes opciones, como vimos en el post sobre
Trident.
Para especificar los volúmenes de nuestros servicios o contenedores, la sintaxis de la opción --mount utiliza determinadas claves, mediante las cuales podemos especificar las siguientes opciones:
- Tipo de montaje, con la opción type. Esta opción nos permite especificar si el montaje será de tipo bind, volume o tmpfs. El tipo tmpfs nos permite crear un volumen en la memoria asignada al contenedor, lo cual está indicado para aquellos datos temporales que no queremos o no es necesario que tengan persistencia.
- Origen del montaje, con la opción source. Para volúmenes con un nombre determinado, este campo contendrá el nombre del volumen. Si no especificamos un nombre se creará un volumen anónimo.
- Ruta o punto de montaje, con la opción destination. Con esta opción especificaremos el punto de montaje dentro del contenedor.
- Resto de opciones, especificadas como volume-opt, que nos permitirán especificar opciones adicionales de configuración.
Recordando el post sobre Trident, creamos un servicio montando un volumen y especificando un driver, del siguiente modo:
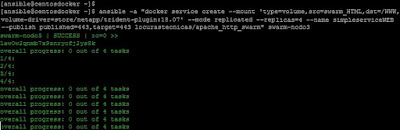 |
| Especificamos un volumen en la creación de un servicio. |
Vamos a revisarlo más detenidamente, definiendo un servicio simple que incluya volúmenes y modificando un servicio ya existente añadiendo o eliminando volúmenes.
Empezando por la parte más sencilla, con el subcomando volume de docker podemos controlar los volúmenes de nuestro cluster swarm, o de dockerhosts individuales. Las opciones disponibles del comando docker volume son las siguientes:
 |
| Opciones disponibles del comando docker volume. |
Si usamos el comando docker volume sin ninguna opción, el driver utilizado será local, es decir las operaciones se realizarán sobre volúmenes locales del dockerhost sobre el que estemos operando. Por ejemplo, podemos crear un volumen en un solo dockerhost:
 |
| Creación de un volumen local en un dockerhost. |
Tambien podemos crear un volumen, con el mismo nombre, en cada uno de los dockerhost que forman parte del swarm:
 |
| Creación de un volumen local en los nodos de un swarm. |
De la salida del comando docker volume ls vemos que, la primera columna indica que el driver utilizado es local. Esto indica que ese volumen solo existe en el dockerhost y por tanto, los datos que un servicio o contenedor genere y almacene en dicho volumen solo estarán disponibles en dicho dockerhost.
Los volúmenes creados con el driver local se crearán siempre en la ruta /var/lib/docker/volumes, lo cual podemos comprobar usando el comando docker volume inspect:
 |
| Obteniendo la información de un volumen. |
Como es lógico, podemos cambiar esta ruta especificando la opción --data-root en el arranque del demonio dockerd.
Ahora que hemos creado un volumen común a todos los dockerhosts del swarm, podemos arrancar un servicio simple que use dicho volumen, especificándolo con --mount, mediante el comando siguiente:
 |
| Creación de un servicio con un volumen local. |
De esta manera, al crear el servicio sin especificar un driver, docker usará el driver local y buscará un volumen con el nombre especificado en el dockerhost para montarlo en los contenedores. En caso de especificar un volumen que no exista, el volumen se creará con el nombre especificado o, si no especificamos un nombre, se creará un volumen anónimo:
 |
| Creación de un servicio con múltiples volúmenes. |
Al listar los volúmenes disponibles en cada uno de los dockerhosts del swarm, vemos que se ha creado el volumen VOL_logs_swarm que no existía antes y dos volúmenes anónimos, uno se corresponde con el volumen para la ruta especificada /WWW_tmp y el otro volumen anónimo es para el volumen indicado en la definición de la imagen usada, que en este caso se monta en /WWW.
 |
| Volúmenes creados para el servicio. |
Por
tanto, docker nos permitirá crear los volúmenes o los creará en caso de
ser necesario, ya que como vemos se crea un volumen anónimo cada vez
que lanzamos un contenedor a partir de una imagen que incluye volúmenes
en su configuración.
Cuando queramos eliminar volúmenes que ya no se usen, podremos usar el comando docker volume prune, lo cual los eliminará. Como es lógico, al no especificar el driver, esto solo se aplicará a los volúmenes locales:
 |
| Eliminamos los volúmenes no usados. En este caso son volúmenes locales. |
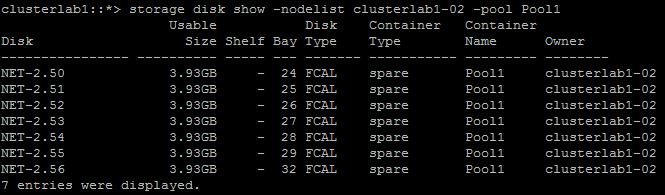
Ahora, usando plugins específicos para la creación de volúmenes para nuestros servicios, como por ejemplo el driver Trident para interactuar con sistemas NetApp, podemos crear un servicio que utilice volúmenes de datos comunes proporcionados por una SVM y volúmenes locales para datos temporales que no necesitamos que se mantengan:
 |
| Creación de un servicio con volúmenes desde una SVM. |
En este ejemplo creamos un servicio que usa un volumen ya existente en la SVM (swarm_HTML), otro volumen que no existe y que el driver creará por nosotros (swarm_LOG) y un volumen local que tampoco existía con anterioridad (LOCAL_tmp) y que Docker creará en cada dockerhost:
 |
| El volumen VOL_swarm_LOG lo creará Trident al crear el servicio. |
 |
| Lista de volúmenes existentes en nuestro swarm. |
Por tanto podemos combinar volúmenes de diferentes poveedores en el mismo servicio con solo especificar el driver correcto para cada uno de ellos. Podemos comprobar los volúmenes en uso por el servicio usando el comando docker service inspect:
 |
| Lista de volúmenes en uso por el servicio. |
En caso de ser necesario podemos actualizar la configuración del servicio y añadir o quitar volúmenes, mediante la opción --mount-rm del comando docker service update. Por ejemplo, si ncesitamos eliminar el volumen local, podemos hacer lo siguiente:
 |
| Eliminamos un volúmen de un servicio. |
Con lo que ahora, al inspeccionar el servicio, vemos que solo está usando los volúmenes proporcionado por la SVM del sistema NetApp:
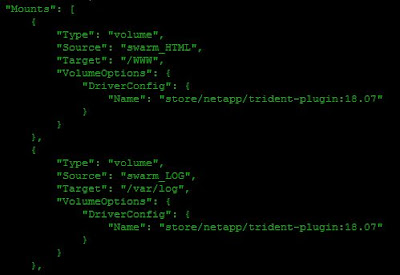 |
| El servicio ahora usa solo dos volúmenes, dados por el driver Trident. |
Para aplicar este update, como vemos en la salida siguiente, Docker ha parado cada contenedor del servicio y lo ha vuelto a arrancar con la nueva configuración:
 |
| Contenedores arrancados con la nueva configuración de volúmenes. |
Por tanto y para terminar, hemos visto como Docker nos permite gestionar los volúmenes necesarios para nuestros contenedores o servicios y su integración con proveedores de almacenamiento como NetApp. Como siempre, para una información mucho más detallada, os recomiendo consultar la documentación oficial de Docker.