Hola, en esta nueva entrada vamos a seguir realizando ejemplos prácticos con Docker y profundizando en sus características, así como extendiendo los ejemplos que realizamos en la entrada anterior.
En el post anterior de esta serie, creamos un contenedor a partir de una imagen de Apache para tener un servidor web. Al hacerlo comprobamos como nuestro sistema descargaba la imagen de Docker Hub en caso de que no la tuviesemos ya, creaba el contenedor y lo ejecutaba.
También comprobamos que no podíamos acceder a este contenedor desde fuera del host que lo albergaba, pero si desde el propio host y como el contenedor si podía acceder al exterior.
Hoy vamos a continuar con este ejemplo y a explorar dos conceptos fundamentales para la implementación de nuestros servicios, la red y el almacenamiento.
Hasta aquí, lo que tenemos es un servidor web el cual es que no es accesible desde el exterior de nuestro host. Si queremos dar servicio a clientes, ¿que tenemos que hacer para que puedan acceder a la web publicada en nuestro servidor? La solución con docker es increiblemente sencilla ya que, lo único que debemos hacer, es crear nuestro contenedor estableciendo un mapeo de puertos con la opción -p para que los puertos expuestos definidos por la imagen, sean accesibles desde el host que ejecuta el contenedor.
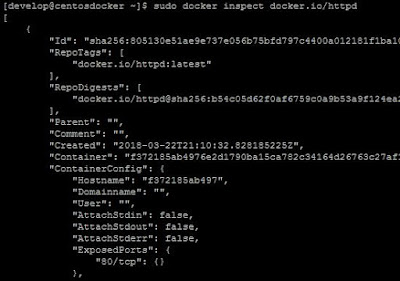
¿Que es eso de los puertos expuestos definidos por la imagen? Como ya he comentado de forma muy resumida, nuestros contenedores hacen uso de imágenes que contienen el software que necesitamos ejecutar. Estas imágenes tienen unas características que podemos consultar con el docker inspect, el cual nos permitirá ver gran cantidad de información sobre cualquier imagen. Si usamos este comando con la imagen httpd que hemos utilizado para crear nuestro contenedor webserver, encontraremos una configuración como la siguiente:
 |
| Comando docker inspect para consultar los puertos expuestos. |
En la imagen anterior, justo al final, podemos ver una entrada que se denomina ExposedPorts que indica que cualquier contenedor creado usando esta imagen, expondrá a la red el puerto 80 para que se acceda al servicio. Como es lógico, al tratarse de una imagen que contiene el software de un servidor web, el puerto que expone para acceder al servicio es el puerto 80 y en general, cada servicio que implementemos podrá tener una serie de puertos expuestos, siempre en función del solftware que esté incluido en la imagen.
Por tanto, teniendo esto en cuenta, si ahora creamos un nuevo contenedor especificando que el puerto 80 debe estar mapeado al mismo puerto en nuestro host, tendremos un comando como el siguiente:
 |
| Contenedor con el puerto 80 publicado en red. |
Ahora, desde cualquier host podremos acceder al servicio web dado por nuestro contenedor:
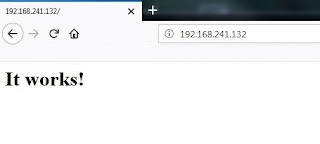 |
| Acceso al servicio web del contenedor. |
En general, cuando necesitemos publicar puertos de red de un contenedor o contenedores, usaremos siempre el comando siguiente a la hora de crearlos:
docker run -p HOSTPORT:CONTAINERPORT [OPCIONES]
De este modo, si por ejemplo ya tenemos otro servidor web escuchando en nuestro host en el puerto 80, podremos crear el contenedor especificando que el puerto 80 expuesto por el contenedor se publique en otro puerto diferente:
 |
| Cambiando el puerto publicado de un contenedor. |
|
Si de nuevo probamos a acceder al host donde está corriendo nuestro contenedor, pero en este caso al puerto 8000, veremos de nuevo nuestra web disponible:
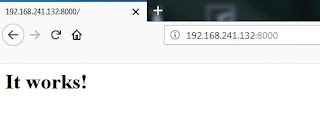 |
| Acceso al servicio web del contenedor. |
La opción -p permite unas cuantas variaciones que, en función de nuestras necesidades, nos permitirá publicar los puertos del siguiente modo:
- -p Puerto_Contenedor, al especificarlo así se enlazará el puerto dado del contenedor con un puerto dinámico en todos los interfaces de red del host.
- -p Puerto_Host:Puerto_Contenedor, este es el ejemplo que hemos utilizado, enlazamos el puerto del contenedor con el puertos especificado del host en todos los interfaces de red del host.
- -p ip::Puerto_Contenedor, al especificarlo así se enlazará el puerto dado del contenedor con un puerto dinámico en el interfaz con la dirección IP especificada.
- -p ip:Puerto_Host:Puerto_Contenedor, enlazamos el puerto dado del contenedor con el puerto específico del host en el interfaz con la dirección IP especificada.
Como es lógico podemos usar la opción -p varias veces con todos los puertos que sea necesario exponer desde el contenedor.
Os recomiendo revisar la documentación oficial de Docker, ya que hay más opciones relacionadas con el control y acceso a la red.
Ya sabemos como controlar el acceso a red de nuestros contenedores y continuando nuestro ejemplo, ya que tenemos un servidor web, lo siguiente es publicar nuestro propio contenido pero, ¿cómo podemos hacer esto? La respuesta a esta pregunta es mediante el uso de volúmenes.
La forma más sencilla de entender un volumen es como un punto de montaje en el host al cual nuestro contenedor tendrá acceso. De este modo, para nuestro servidor web, lo único que necesitamos es volver a crear el contenedor especificando el volumen o volúmenes a los que tendrá acceso.
Por ejemplo, vamos a crear una página web muy simple y vamos a darle acceso de lectura al nuevo contenedor. Para esto solo tenemos que crear nuestro contenedor con la opción -v y la especificación de rutas a utilizar, por ejemplo, para nuestro servidor web sería algo como lo siguiente:
 |
| Creación de un contenedor con un volumen. |
En este comando hemos expuesto el puerto 80 del contenedor en el puerto 80 del host y además, hemos añadido la opción -v indicándo que la ruta local /home/develop/HTML está disponible y accesible para el contenedor en la ruta /usr/local/apache2/htdocs con lo que, si lo hemos hecho todo bien, al acceder con un navegador web al puerto 80 de nuestro host veremos nuestra página web.
De esta manera tan sencilla los contenedores acceden a contenidos que queremos servir, como por ejmplo el contenido de un servicio web, conseguimos permanencia de los datos generados por clientes de nuestro servicio, como en el caso de un servicio de base de datos, etc...
Al usar volumenes es necesario tener en cuenta lo siguiente:
- Un volumen puede ser compartido por varios contenedores. Evidentemente es importante tener en cuenta el tipo de acceso que se va a realizar ya que, si se realizan escrituras será necesaria considerar el uso de algún tippo de sistema de archivos de cluster como GFS2.
- Al montar un volumen en una ruta de un contenedor, el contenido de esa ruta dentro del contenedor se sustituye por lo que tengamos en nuestra ruta.
- En caso de especificar uan ruta dentro del contenedor que no existe, dicha ruta se creará para permitir el montaje de nuestro volumen.
Con el ejemplo anterior hemos dado acceso a un directorio de nuestro host a un contenedor. Imaginemos que debido a un bug, un intruso es capaz de acceder al contenedor y por tanto, a dicho directorio local en nuestro host. Para limitar el daño que podría hacer podemos especificar que el acceso a dicho volumen, se en modo solo lectura. Para esto solo tenemos que crear el contenedor con la opción -v añadiendo :ro al final, como en el siguiente comando:
 |
| Creación de contenedor con volumen de solo lectura. |
|
De este modo tenemos nuestro servidor web accediendo a nuestro contenido, pero ahora solamente en modo lectura.
Vamos a comprobar este último punto y así revisar algunas de las opciones que podemos utilizar en línea de comandos y que, hasta ahora, hemos venido usando.
Hasta ahora, en todos los comandos hemos utilizado la opción -d, la cual le dice a docker que queremos crear o arrancar un cotenendor sin tener acceso a sus salidas estándar stdout, haciendo así que se ejecute en background. Como ejemplo, si creamos un nuevo contenedor como nuestro servidor web, sin usar la opción -d veremos lo siguiente:
 |
| Contenedor corriendo en primer plano. |
Al ejecutarse así veremos en consola toda la salida que los procesos del contenedor estén enviando a stderr y stdout y nos desconectaremos parando el contenedor, pulsando CTRL+C.
Ahora, para comprobar como hemos dicho, que nuestro volumen está montado en modo solo lectura, vamos a lanzar un comando en nuestro contenedor para intentar crear un fichero en dicha ruta. Para esto solo debemos usar el subcomando exec:
 |
| Volumen de solo lectura. |
|
De este modo nos aseguramos de proteger nuestro hoost local y deberíamos tomar como buena práctica que los contenedores solo tengan acceso de escritura a aquellos volúmenes donde realmente necesiten escribir.
Hasta aquí la segunda parte de las prácticas de Docker, en breve la siguiente en la que intentaremos relacionar cotenedores y describir servicios.